学位論文要旨
| No | 111155 | |
| 著者(漢字) | 古賀,弘樹 | |
| 著者(英字) | Koga,Hiroki | |
| 著者(カナ) | コガ,ヒロキ | |
| 標題(和) | 忠実度規範つき情報源符号化アルゴリズムに関する研究 | |
| 標題(洋) | A Study of Source Coding Algorithms with Fidelity Criterion | |
| 報告番号 | 111155 | |
| 報告番号 | 甲11155 | |
| 学位授与日 | 1995.03.29 | |
| 学位種別 | 課程博士 | |
| 学位種類 | 博士(工学) | |
| 学位記番号 | 博工第3399号 | |
| 研究科 | 工学系研究科 | |
| 専攻 | 計数工学専攻 | |
| 論文審査委員 | ||
| 内容要旨 | 近年の通信ネットワークの発達に伴い,動画などの大規模なデータを高速に伝送する必要が高まっている.通常の通信路を介してデータを伝送する場合には,データ圧縮技術を使ってデータのもつ冗長性を取り除くことによって,効率的なデータ伝送が可能になる.特に画像や音声のデータは,元のデータと再生されるデータに許容できる程度の歪を許せば,より高いデータ圧縮率を得ることができる.本論文ではこの歪を許す符号化をレート・歪理論の立場から考察する. 定常エルゴード的な情報源を歪を許して圧縮するとき,符号化によって達成可能なデータの圧縮率はレート・歪関数と呼ばれる歪の関数になる.レート・歪関数を漸近的に達成するブロック符号の存在は,情報源符号化定理によって保証される.ところが,情報源符号化定理は一般に広い情報源のクラスに対して構成的でない形で証明されるので,漸近的にレート・歪関数を達成する符号の実体が明確でない.本論文では離散無記憶情報源とガウス性無記憶情報源の2つの情報源クラスに対して,漸近最良性をもつ符号化法のもつ性質を明らかにするとともに,その符号化法をユニバーサルな形で実現する方法について議論する. この章ではガウス性無記憶情報源に対するブロック符号化法を提案し,情報源の平均と分散が既知,未知の各場合に符号化法のもつ漸近的な特性を解析する.情報源が既知の場合は一般性を失うことなく平均0,分散1を仮定できる.情報源が出力する系列の長さnのブロックをx=(x1,x2,…,xn)Tで表すとき,そのユークリッドノルム||x||2がスカラー量子化器によって,x/||x||2がn次元単位超球Sn-1上の点集合Y={y1,y2,…,yM}によってそれぞれ符号化される.符号化は以下の写像 ここでarg 1)任意に固定した 2) 3)Lはnの多項式のオーダーである, を満たすとき,漸近的な特性が で表される漸近最良な符号化が行えることが証明できる.この符号化法では漸近的な特性は主にスカラー量子化器によって決定される. 上記の符号化法は2パス符号化によって平均または分散が未知の情報源に対しても拡張できる.未知パラメータはある既知の有界領域に属するという仮定をおくと,情報源ブロックxと 1977年に発表されたLempel-Ziv符号は定常エルゴード的な情報源に対して漸近的にエントロピーを達成する.いま と定義すると, がレート・歪関数に確率収束する十分条件を,離散無記憶情報源とガウス性無記憶情報源の2つの情報源クラスについて導出し,その結果自然に導かれる符号化法についての議論を行う. 最初にアルファベットA={a1,a2,…,aJ}をもつ離散無記憶情報源を考察する.A上の確率分布をpで表し,j=1,2,…,Jに対してp(aj)>0を仮定する.d:A×A→[0,∞)をd(aj,ak)=0(j=k),d(aj,ak)>0(j≠k)を満たす1シンボルあたりの歪測度とし,ブロック で定まるA上の確率分布をp*と記す.このとき,任意の ここにD(p*||p)はダイバージェンスである.また,qをp*(aj)>0なるすべてのaj∈Aに対してq(aj)>0を満たすA上の任意の確率分布とすると,任意の が成り立つことも示される.Qはqから導かれるXの確率測度,P|i,j|は確率測度の 次に平均0,分散 とおくと, 情報源が離散無記憶のとき,与えられた歪水準 有限アルファベットA={a1,a2,…,aJ}をもつ情報源の確率分布をpで表す.推定アルゴリズムはq(aj)>0,j=1,2,…,Jを満たす確率分布qの補助情報源の出力が利用できると仮定する.最初の推定アルゴリズムは情報源の長さnのL個のブロックX={x1,x2,…,xL}と補助情報源の長さnのM個のブロックY={y1,y2,…,yM}を使ってp*の推定値 を満たすという規範を課す.上式のProbはX×Yに関する確率を表す.規範(12)を満たす確率分布 を満たす.ここに この推定アルゴリズムは,任意に固定した と定義する. この推定アルゴリズムが実際に規範(12)を満たす 同様の問題設定のもとで,2番目の推定アルゴリズムは情報源からX={x1,x2,…,xL}を,補助情報源から | |
| 審査要旨 | 近年のディジタル通信技術の発展や通信ネットワークの発達に伴い、大量でかつ多種多様なデータを高速かつ適格に伝送する技術の確立が要求されている。特に、画像やビディオ信号のデータは画面当り、あるいは、単位時間当りのビット数が大きく、記録や伝送の各過程でより高いデータ圧縮率をはかることが必要になっている。本研究は、これら大規模データのデータ圧縮の問題を忠実度規範のもとで復元歪を許すレート・歪理論の枠組みに基づいて研究している。レート・歪理論はシャノンによって1960年前後に定式化され、基本的な符号化定理は1970年代中頃にランダム符号化の考え方に基づいて証明されたはしたが、具体的な符号化法の研究は長い間等閉に付され、特殊な情報源を除いては一般的な符号構成法は示されていない。本研究はこのような未解決問題に挑戦し、ガウス性無記憶情報源と離散的無記憶情報源に限ってではあるが、実現可能な符号構成法を示し、その性能解析を行ったものである。 本論文は、「忠実度規範つき情報源符号化アルゴリズムに関する研究」と題し、4章から構成されている。第1章では、本研究の動機を述べ、レート・歪理論の発展の歴史と研究の現状をまとめるとともに、本論文の概略を与えている。第2章では、連続値情報源として代表的なガウス性無記憶情報源を考察し、情報源の平均と分散が既知である場合と未知である場合についてそれぞれブロック符号化法を提案している。符号化法の基本は、与えられた長さnの系列のユークリッドノルムの値に関するスカラー量子化と、系列のn次元ベクトルのn次元単位超球面への投影に関する超球面ベクトル量子化によって構成される。ブロック長を大きくするとき、この符号構成が漸近的に最良になることを示すとともに、2パス符号化によって平均または分散が未知の情報源に対してもこの符号化法が拡張できることを示す。また、ブロック長nとともにレートと平均歪が取る漸近的な特性を導出し、Sakrisonによって得られたレートと平均歪に関する限界に比して、よりタイトな限界を得ている。第3章では、離散無記憶情報源とガウス性無記憶情報源について、無歪ユニバーサル符号化法として知られるLempel-Ziv符号化法をストリングマッチングのもとで拡張して使う方法を解析している。まず、適当な歪測度と固定した歪水準のもとで定義される系列の有歪再帰時間がレート・歪関数とある付加項の和に確率収束する十分条件を導出し、この付加項の形から自然に導かれる符号化法を提案している。すなわち、ブロック長nを大きくしたとき、有歪再帰関数は、レート・歪関数に情報源確率分布pと相互情報量を最小にするテスト通信路から決まる出力分布p*とのダイバージェンスを加えた値に収束することを証明している。これは、Steinberg-Gutmanの結果の自然な拡張となるとともに、よりタイトなレート・歪関係を与えており、しかも、この結果から情報源の確率分布が既知のときレート・歪関数に漸近的に近づく符号器と復号器が構成できることが示される。第4章では、無記憶情報源を扱い、与えられた歪水準に対応するテスト通信路行列から決まる出力確率分布p*を推定するユニバーサルな推定アルゴリズムを提案し、推定に必要なサンプル数を評価している。このアルゴリズムは、PAC学習法として知られる方法を拡張することによって得られており、今まで無歪符号化の方法としてしか考えられなかったユニバーサル符号化が有歪符号化にも適用し得ることを示すきっかけを与えたものと解釈できる。また、ブロック長nが十分大きくなるときのテスト通信路および出力確率分布の推定量の満たすべき条件を導出し、漸近的特性を評価している。最後に、今まで得られた結果がレート・歪理論の発展に果たす意義を述べ、今後の研究の展開を展望している。 以上を要約すれば、本研究はレート・歪理論の基本的な符号化定理を具体的な符号構成法を示すことによって証明しており、構成的証明の第一歩を与えたものとして評価できる。また、ストリングマッチングの方法とPAC学習の方法を結びつけることによって、歪規範のもとでのデータ圧縮についてもユニバーサル符号化の考え方が成立し得ることを見出しており、情報理論ならびにデータ圧縮技術に大きく貢献している。よって本論文は博士(工学)の学位請求論文として合格と認められる。 | |
| UTokyo Repositoryリンク | http://hdl.handle.net/2261/54453 |
 =(
=(

 は内積〈x,y〉を最大にする引数を表し,A={a1,a2,…,aL},C={c1,c2,…,cL}は0=a1
は内積〈x,y〉を最大にする引数を表し,A={a1,a2,…,aL},C={c1,c2,…,cL}は0=a1 c1
c1 と書いて平均歪と呼ぶ.xはcl,ymの添字を復号器側に伝えることによって伝送され,この符号化に必要なレートは1シンボルあたりR=
と書いて平均歪と呼ぶ.xはcl,ymの添字を復号器側に伝えることによって伝送され,この符号化に必要なレートは1シンボルあたりR= Mビットである.また,分散1のガウス性無記憶情報源に対するレート・歪関数はD∈(0,1]に対して
Mビットである.また,分散1のガウス性無記憶情報源に対するレート・歪関数はD∈(0,1]に対して と書ける.Mを任意に固定した歪水準
と書ける.Mを任意に固定した歪水準 ∈(0,1)に対して
∈(0,1)に対して )と定め,A,Cが次の3条件
)と定め,A,Cが次の3条件 >0に対して
>0に対して
 は
は を満たす.
を満たす.
 Mビット,未知情報源の場合はさらに未知パラメータ1つあたり
Mビット,未知情報源の場合はさらに未知パラメータ1つあたり ビット,加えて分散が未知の場合には
ビット,加えて分散が未知の場合には ビットが余分に求められる.
ビットが余分に求められる. を有限アルファベットAに値をとる定常エルゴード的な確率変数列,
を有限アルファベットAに値をとる定常エルゴード的な確率変数列, をXの実現値,PをXの確率測度とし,任意のi
をXの実現値,PをXの確率測度とし,任意のi
 と定める.正整数nに対して正整数Mn(x)を
と定める.正整数nに対して正整数Mn(x)を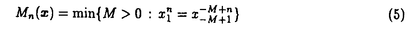
 (x)はエントロピーに確率収束し,この事実はLempel-Ziv符号の1つの理論的基盤を与えている.この章では適当な歪測度dnと任意に固定した歪水準
(x)はエントロピーに確率収束し,この事実はLempel-Ziv符号の1つの理論的基盤を与えている.この章では適当な歪測度dnと任意に固定した歪水準
 ,
, ∈An間の歪dnを文脈自由の形で定義する.この情報源に対するレート・歪関数をR(p,D)と書く.歪水準
∈An間の歪dnを文脈自由の形で定義する.この情報源に対するレート・歪関数をR(p,D)と書く.歪水準
 >0に対してMn(X,
>0に対してMn(X,

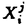 への制限である.特にq=p*のときは
への制限である.特にq=p*のときは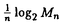 (X,
(X, 2のガウス性無記憶情報源を対象とする.情報源アルファベットAは実数Rに等しく,u,
2のガウス性無記憶情報源を対象とする.情報源アルファベットAは実数Rに等しく,u, ∈Aに対して歪測度dをd(u,v)=(u-v)2,ブロック間の歪を文脈自由の形で定める.歪水準
∈Aに対して歪測度dをd(u,v)=(u-v)2,ブロック間の歪を文脈自由の形で定める.歪水準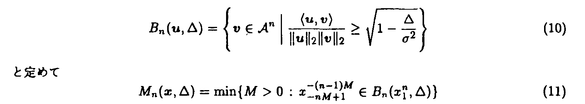
 (X,
(X, を出力する.歪は前章と同様に定義する.推定アルゴリズムには,任意に固定した
を出力する.歪は前章と同様に定義する.推定アルゴリズムには,任意に固定した >0と
>0と
 >
>
 は
は e∈(0,
e∈(0, ]に対して
]に対して を満たすpの推定値
を満たすpの推定値 をもつことを仮定する.また与えられたX,Yに対して,
をもつことを仮定する.また与えられたX,Yに対して,
 ノルムである.推定アルゴリズムは以下の手順でp*を推定する.
ノルムである.推定アルゴリズムは以下の手順でp*を推定する.

 ,nの下限を
,nの下限を ととればよいことが証明できた.また,規範(12)は計算論的学習理論におけるPAC学習モデルと同種のモデルであり,シャノン理論とPAC学習モデルに内在する関係を初めて明らかにしたという意味をもっている.
ととればよいことが証明できた.また,規範(12)は計算論的学習理論におけるPAC学習モデルと同種のモデルであり,シャノン理論とPAC学習モデルに内在する関係を初めて明らかにしたという意味をもっている. を得てp*の推定値
を得てp*の推定値 としてアルゴリズム中のパラメータを適当に選べば,任意の推定精度をもつ
としてアルゴリズム中のパラメータを適当に選べば,任意の推定精度をもつ