| 内容要旨 | | 記憶に基づく推論(Memory-Based Reasoning: MBR)の特徴は,ルールのような抽象度の高い表現では知識を保持せず,大量に蓄積された事例(問題とその回答の組)を直接用いて推論を行なう点にある.質問に対しては,蓄積された事例の中からその質問に最も類似した事例を検索し,類似事例の回答を,そのまま質問の回答とする.新しい知識の学習は,基本的に新しい事例を事例ベースに追加するだけである.MBRは,最も簡単な学習である暗記学習に近い枠組みだが,質問と完全に一致する事例が記憶されていなくても,類似事例により回答を生成できる点が異なる. MBRでは,事例間の類似度の計算方法,具体的には事例を構成する属性の重み付け手法が正答率に大きな影響を与える.これまでに,属性の重み付け手法は多数提案されてきたが,手法間の比較や,対象とするデータの特性と手法の優劣との関係の解析は十分には行なわれていなかった.また多変量解析などの,MBRと同種の問題を対象にする他の手法との比較も不十分であった. 本研究では,まず13種類のベンチマークデータを用いて,各種の属性重み付け手法間の実験的比較を行なった.具体的には,条件付き確率を元にした方法(PCF,CCF,VDM),相互情報量を元にした方法(MIC),等重み値法(NN),incrementalな方法(IB4)を評価対象とした.また広く用いられている統計的手法である主成分分析(PCA)および数量化II類(QM2)と,数量化II類の事例ベースへの拡張(QM2y,QM2m)との比較も合わせて行なった. ベンチマークデータによる比較実験の結果,クラス毎の分散を最大化するように属性を独立化する数量化II類(QM2,QM2y)が,主成分分析や他の属性重み付け手法と比較して高い正答率が得られることがわかった(表1).また,従来の属性重み付け方法の中のいくつかは,重み付け計算のコストが小さいことから大規模データに対して有効であることがわかった.  表1:最高正答率を得たベンチマーク数と属性重み付け手法との関係 表1:最高正答率を得たベンチマーク数と属性重み付け手法との関係 一般に,MBRに限らず概念学習のアルゴリズムの評価には,現実世界の問題から得られたベンチマークデータがよく用いられる.ベンチマークデータを用いた評価の利点としては, 広く流通しており他の実験結果との比較が容易な点,現実世界での事象を元にしており恣意性が少ない点などが挙げられる.その反面,どのデータをいくつ使って評価実験を行なえばいいのかの指針が明らかでない点などが問題点として指摘できる.これらの問題点を解決するため,本研究では人工的にデータを合成し,それらを用いた実験によってアルゴリズムの評価を行なう方法を提案した. 人工データによる評価の利点は,特性が既知であるデータを,必要な数だけ合成できる点にある.したがって,どのデータ特性がアルゴリズムの振舞いに影響しているかを,実験的に知ることができる.一方で,人工データを合成する際にはパラメータの選択が問題になる.データの特性を決定づけるパラメータが含まれていない場合には,一部の偏ったデータしか作成されず,アルゴリズムの評価も偏る可能性がある. 本論文ではまず,データを構成する属性間の依存度が,人工データ合成の際に不可欠なパラメータであることを示した.具体的には,属性間の依存度を制御可能な,人工データ合成プログラムを作成し,これによってデータの属性間の依存度を変化させた場合のアルゴリズムの振舞いの変化を調査した.図1から分かるように,属性間の依存度により正答率が大きく変化するため,属性依存度が重要なパラメータであることが分かる. 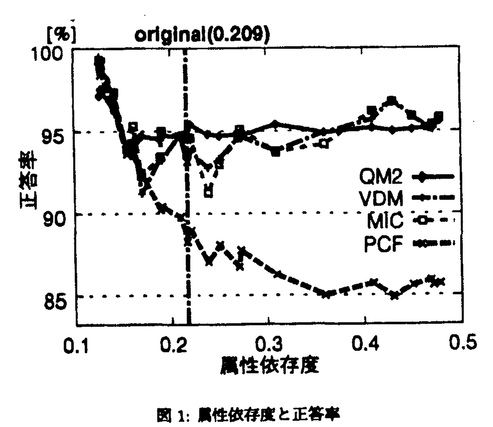 図1:属性依存度と正答率 図1:属性依存度と正答率 また,あらゆるデータに対して良い正答率を挙げる学習アルゴリズムは存在しないことが証明されているため,対象とするデータを絞り込む必要がある.そこで本論文では,対象とするデータを「現実世界」から得られるようなデータに限定した.現実世界という概念は曖昧であるが,現実世界から得られたベンチマークデータを基準として用い,これらのデータに類似した特性をもつパラメータのみによってデータを合成した.このパラメータには属性依存度が含まれている.これらの人工データを用いて,データ特性とアルゴリズムの優位性との関係を明らかにした. 図2に,合成した1536種類のデータのうち,どれだけの割合で良い正答率が得られたかを示す.VDM,MICの両手法は,データ空間中の6割以上の点で良い正答率が得られているのが分かる.一方,図3に示されるように,数量化II類(QM2)は単独で高い正答率を得る頻度が高く,他の手法とは異なるデータで高い正答率を挙げているのが分かる.これは,数量化II類が属性値の平均値によって分類を行なうのに対して,他の手法が事例毎の属性値を用いて分類するためである.  図表図2:人工データ空間で最高(もしくは同等)の正答率が得られた割合 / 図3:手法が単独で良い正答率を得る場合 図表図2:人工データ空間で最高(もしくは同等)の正答率が得られた割合 / 図3:手法が単独で良い正答率を得る場合 最後に,記憶に基づく推論を天気予測に応用する研究を行なった.天気予測は大規模で実用的なアプリケーションであるだけではなく,事例の特性がベンチマークデータと大きく異なり,MBRの例題としても興味深い.記憶に基づく推論を天気予測に応用したシステムWINDOMは,アメダスなどの気象庁の観測網から得られた9年分の観測データを事例として蓄えており,現在の気象状況と最も類似した過去の時点を検索し,それを参考にすることで,数時間先の東京近辺の降水有無を予測する. 図6に,利用する観測データの年数と正答率との関係を示す.このように観測データ量の増加などが正答率の向上に効果的であることが確認された.図4,5には,それぞれ3時間後,9時間後の東京の降水有無を予測する場合の,降水量属性の重み値を示す.予測時間が先になるにつれて,重みが大きく,予測に重要である観測点が西に推移しており,天気が西から変化する特性が反映されていることが分かる.また,図7に,気象庁の関東甲信地方の予報と,WINDOMの予測との比較を示す.WINDOMの正答率は,一都六県の平均値では劣るものの,一部の地区では気象庁の平均正答率と同等の正答率が得られており,天気予測におけるMBRの有効性を示すことができた.  図表図4:3時間後予測での降水量属性の重み値 / 図5:9時間後予測での降水量属性の重み値 図表図4:3時間後予測での降水量属性の重み値 / 図5:9時間後予測での降水量属性の重み値 図表図6:データ量と正答率との関係 / 図7:気象庁による予測の正答率との比較 図表図6:データ量と正答率との関係 / 図7:気象庁による予測の正答率との比較 以上のように本論文は,MBRについて属性重み付け手法を様々な方法で解析・評価し,天気予測に応用して実用性を検証したものである. |