| 1はじめに 計算機技術の革新的な発達により、数値解析が理論、実験に次ぐ手法として確立され、有限要素法などの数値解析手法に要求される解析規模の巨大化、複雑化に伴い、計算機にはより強力な計算能力(CPU)と、膨大な記憶容量(メモリ)が必要不可欠となってきている。最近のスーパーコンピュータなどにみられるように、これらは日々進歩しているが、それらの能力も限界に近づきつつある。そこで近年並列計算機が注目されている。 並列計算機では個々のプロセッサの能力やメモリ規模をそれほど向上させなくても、多数のプロセッサを使用することにより全体として高い性能が得られる。プロセッサの数には物理的制約がないので、基本的にはその能力向上に限界はない。並列計算機では、単一のスーパーコンピュータでは解けない大規模な問題も高速に解くことができる。並列計算機の中でも特に多数のプロセッサを備えた超並列計算機は、既にかなりの性能を備えたものが開発されている。このように大変魅力的な特徴を有する並列計算機ではあるが、その性能を十分に引き出すためには並列処理用のアルゴリズムを必要とする。 それに伴い、有限要素法等の数値解析手法の並列化に関する研究も盛んに行われている。しかし従来の並列化手法では、解析対象の形状が複雑になると、プロセッサ間の負荷バランスがとりにくくなり、また比較的少ないプロセッサ数でプロセッサ数の増加に対する速度向上が飽和してしまう、という問題点が多々存在した。これらの問題点を解決する手法として、本論文では領域分割法による有限要素法の並列化を提案した。領域分割法はハードウェアによらず、高い粒度が得られるので並列計算機に適しており、これまでにトランスピュータ、EWSネットワーク、スーパーコンピュータ・ネットワークへの適用が進められてきた。 本論文では領域分割法での複雑形状大規模解析を行うために必要となる、自動前処理システム、境界問題における収束回数の減少を目的とした、前処理付き共役勾配法の導入、階層型領域分割法のアルゴリズムの開発を行い、超並列計算機上で大規模解析を実現しその有効性を示した。 2領域分割法に基づく並列有限要素法 領域分割法とは、一つの解析領域を複数の小さな部分領域に分けて解析する手法である。領域間の解に連続性を持たせるために反復解法を用いる。すなわち、初期値として部分領域間の境界に適当な境界条件を与え、各部分領域の解析後、領域間の境界で解が連続するように、境界条件を更新し、再び各領域ごとに解析を行う。この操作を境界値が収束するまで繰り返す。この手法を用いると、反復計算が必要になるものの、分割された小領域を解析するための記憶容量のみで十分なので、記憶容量が小さい計算機でも大規模解析が行える。 領域分割法では、各部分領域での有限要素解析が完全に独立に行えるので並列処理が可能である。そこで解析領域全体を複数個の領域に分割後、各部分領域の有限要素解析を並列に行い、全領域での解析が終了したのち、領域間の境界上で解が連続するように各領域での境界条件を修正し、再び解析を行う。この操作を境界値が収束するまで繰り返し、解を求めることにより並列化を実現する。 領域分割法では、境界問題を解く反復手法として共役勾配法を用いることができる。一般的に共役勾配法では前処理を行うことにより、反復回数を大幅に減少させることができる。領域分割法における共役勾配法では、内部境界上のデータの変換を行う正値対称な作用素を設定するが、この作用素の近似作用素を使用することにより、前処理を実現することができる。 3並列計算機への適用 本研究では、MIMD型の超並列計算機、nCUBE2(1,024CPU構成)、CM5(32CPU構成)、Cray-T3D(256CPU構成)を使用し、必要なデータをCPU間の通信により交換するメッセージパッシングにより、並列化を実現している。また、経済的である、複数のワークステーションをネットワークで介し、ひとつの並列計算機のように使用するワークステーションクラスタも利用した。 領域分割法を並列計算機に実装するに際し、1つのCPUを親プロセッサとし、それに全領域のデータを読み込ませ、残りのプロセッサを子プロセッサとし、それらに親プロセッサから分割後の領域のデータを送り、子プロセッサ内で解析を行わせた。この際子プロセッサに送る領域は特定せずに、受け取り準備ができたら、順次親プロセッサから領域のデータを送った。この操作を行うことにより、複雑形状の解析対象に対しても子プロセッサ間での負荷バランスをとることが可能となる。解析終了後に親プロセッサに解析結果を送り、すべての領域の解析が終了した後、親プロセッサが領域間の解が連続するよう共役勾配法のアルゴリズムに従い境界条件を更新し、再び子プロセッサにデータを送り解析を行わせる。この操作を解が収束するまで繰り返し全体の結果を得る。この手法を用いると、1つの親プロセッサに全ての入力データを読み込ませるため、解析規模の大きさの上限値がメモリ容量により制限され、また全ての子プロセッサとの間でデータ通信を行うため、通信の負荷が親プロセッサに集中してしまう。そこでこの問題を解決するために、親プロセッサを複数個設け、入力データおよび通信負荷を分散化し、より大規模な問題を解析可能とした階層型領域分割法を開発した。 階層型領域分割法ではあらかじめ複数個に分割された入力データを、同数個用意した親プロセッサにそれぞれ読み込ませ、親プロセッサでは読み込んだデータを領域毎に子プロセッサに送り、子プロセッサ内で解析を行わせる。すべての領域の解析が終了した後、親プロセッサはそれをさらに1つ設けている祖父プロセッサに送る。すべての親プロセッサから結果が集まった後、祖父プロセッサが領域間の解が連続するよう共役勾配法のアルゴリズムに従い境界条件を更新し、再び親プロセッサにデータを送り、親プロセッサはそのデータを子プロセッサに送り解析を行わせる。この操作を解が収束するまで繰り返し全体の結果を得る。プロセッサ間でのデータの流れの様子を図1に示す。  Fig.1 Schematic Data Flow among Processors4超並列大規模有限要素解析のための前処理システム Fig.1 Schematic Data Flow among Processors4超並列大規模有限要素解析のための前処理システム 有限要素法においては、解析対象をあらかじめ有限個の要素に分割するために、形状定義、節点発生、メッシュ生成といった前処理を施す必要がある。従来はその多くを人手に頼っていた前処理技術についても解析対象が大規模、複雑化することにともない、自動化、高速化が要求されている。 領域分割法による並列有限要素法については、生成された要素を領域に分割する独自の前処理システムが必要となり、また階層型領域分割法では、領域分割を入れ子的に行うシステムが必要となる。そこで、これらのシステムを構築し、大規模複雑形状モデルへ適応した。 本システムで生成したメッシュ例を図2に示す。原子炉圧力容器モデルの形状を定義し、節点発生、要素分割を行った結果である。このメッシュに対し更に領域分割、部分分割を行う。形状定義にはやや手間が掛るものの、その後の処理はほぼ全自動であり、本解析システムに十分対応している。  Fig.2 Pressure Vessel Model5圧力容器の解析 Fig.2 Pressure Vessel Model5圧力容器の解析 領域分割型並列有限要素法をMIMD型の超並列計算機、nCUBE2(1,024CPU構成)、CM5(32CPU構成)、Cray-T3D(256CPU構成)および合計16CPUとなるワークステーションクラスタを使用し解析し、その結果を比較した。解析例として図2に示す原子炉圧力容器モデルの弾性解析を4面体2次要素200,388自由度、586領域モデルを用いて行った。5 反復回数での計算時間の結果を表1に示す。nCUBE2の解析ではメモリの制限により複数の親CPUが必要となり、全体でのCPU利用率はやや低い値となっているが、実際に解析を行っている子CPUについては95%を越える利用率を示している。またワークステーションクラスタについては、使用している通信に利用するネットワークが並列計算機に比べ低速なため、やや低い効率となっている。  Table 1 Calculation time and parallel performance Table 1 Calculation time and parallel performance 大規模、複雑形状の解析例として上述のモデルを220,245個の要素、6,076領域に分割し、1,024CPU構成のnCUBE2を用いて解析を行った。自由度数は1,045,107となる。CG法に前処理を用いたケースと用いていないケースの収束の様子を図3に示す。前処理技術により6,698回の反復計算で収束を得られ、182時間、96.5%の効率で解析を実現した。 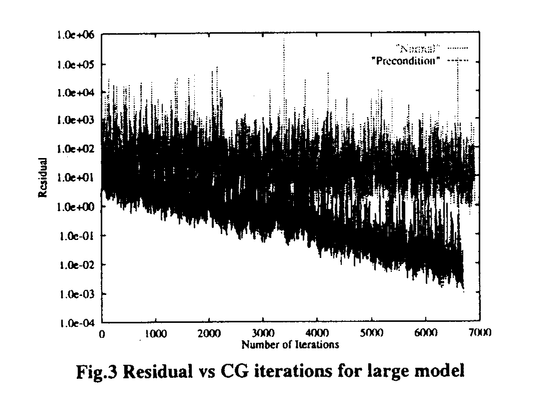 Fig.3 Residual vs CG iterations for large model Fig.3 Residual vs CG iterations for large model 以上の結果から高効率のもとで超並列計算機上での3次元大規模有限要素解析の並列処理が実現されているのがわかる。 6おわりに 領域分割法に基づく並列有限要素解析システムおよび、自動メッシュ生成システムを構築し、超並列計算機に適用し構造解析を行った。計算機に依存せず高効率が得られ、また大規模(100万自由度規模)の構造解析を高効率のもとで実現した。 |