| 内容要旨 | | 因子分析は心理学などで頻繁に用いられる多変量解析法の一つである.しかし,適用対象が主に人間の非物理的,潜在的側面であるために,測定方法の制約や被験者側の要因によって因子分析を適用する際の前提条件が満たされない場合がある.そしてこのようなデータに対して因子分析を適用した結果は歪曲されている可能性がある. 本研究では因子分析モデルを様々な形態のデータに適用し,推定結果に悪影響を生じるデータの条件や因子分析方法の調査をおこなう.また,その過程で派生した問題の解決策の提案をおこなう. 因子分析における初期値,解法が推定結果に及ぼす影響 共通性推定の初期値の違い,因子負荷量を求める方法の違いが推定された因子負荷量行列に与える影響を調べるためにシミュレーション実験をおこなった.操作した要因は,共通性推定の初期値(SMC,1.0,他変数との相関の絶対値の最大値,0-1間の乱数の4種)と解を求める方法(アルファ因子分析,最尤法,主因子法,反復あり主因子,最小二乗法の5種),観測数(50,100,150,200,300の5種)である. 条件の組合せごとに100組ずつ,真の因子数と因子負荷量行列が既知の因子分析モデルにしたがった人工データを発生し,因子分析法を適用した.評価の指標は因子負荷量行列の再現性(乖離指数),不適解の発生数である. 従来,SMCは初期値として優れているとされてきたが,他変数との相関の絶対値の最大値を初期値とした場合と有意な違いは見られず,不適解の発生数は乱数条件を除く3種中最多であった.また(1)最尤法は観測数が50のとき約30%の不適解を生じた,および,(2)推定が正しく収束した場合,初期値によって因子負荷量行列の再現性には違いがみられないなどの結果を得た. 因子分析法の適用が不適切な条件の検討 因子分析法は連続値データだけではなく,質問紙調査における回答のように順序性のあるカテゴリカルデータに対して適用されることがある.これらの状況下で因子分析の適用が不適切な条件を明らかにするために真の因子数及び因子負荷量が既知の人工データを,いくつかの要因を操作した上で発生し,因子分析法を適用するシミュレーション実験を2種類おこなった. 実験1では,因子負荷量行列の再現性,不適解の発生数を指標としてデータ要因の影響の比較をおこなった.実験2ではAIC,BICの因子数決定基準を用いて,真の因子数が最適な因子数として選択される回数を指標としてデータ特性の影響の比較をおこなった.操作した要因は,カテゴリ数(2,3,5,7,カテゴリなし=連続値条件の5種),観測数(50,100,200,300の4種),項目数(15,30の2種),因子数(3,5の2種),データの度数分布型(均一型,負の歪み型,中央に山型,中央に谷型)のデータ特性と,相関係数の推定方法(簡便法,Olssonの方法)である. シミュレーションは,実験1,2ともにデータ特性の組合せごとに100組ずつデータを発生させ,2種類の方法で相関係数の推定を行い,因子分析法を適用するという手順で行われた.因子負荷量の推定にはSASのFACTORプロシジャの最尤法を使用し,共通性推定の初期値はSMCとした. 結果として,シミュレーションをおこなった条件内で因子分析の適用に注意を要すると考えられるデータ特性は次の4点に要約される. ・カテゴリ数が少ない場合:観測数が十分に多いならば,おおむね因子負荷量行列の再現性は連続値条件でもっとも良く,カテゴリ数が減少するにつれて悪くなる.2件法,3件法のデータに対して因子分析を適用することは好ましくない. ・項目数が少ない場合:データの形態に依存せず,項目数が少ない場合には因子負荷量の再現性が悪い等の現象が観測された. ・(真の)因子数が多い場合:項目数と観測数が同じであるならば,データの形態によらず,(真の)因子数の多い方が因子負荷量の再現性は悪化し,計算不能回数も増加した,項目数と因子数に関して個々の因子に対して関与する項目が最低3つ存在する方がよいというルールが提案されているがこのルールは必ずしも十分ではない. ・観測数が少ない時:因子分析を行なう場合に必要とされる観測数は,データの度数分布の特性,カテゴリ数,項目数,因子数などの様々な要因の影響を受けて変化する.Olssonの方法で相関係数を推定する場合や,真の因子数が多く項目数が少ない場合等では観測数が200であっても不十分である.単純に観測数が"100個以上ある"という理由で安心して因子分析法を適用することはできない. データの度数分布型の影響は顕著ではないが,カテゴリ数が少ない等の他の悪条件と中央に谷型条件という条件が重なる場合,因子負荷量行列の再現性は悪くなる.相関係数の推定方法に関しては,(1)因子負荷量の再現性には違いが見られない,(2)Olssonの方法は計算不能回数が数倍多いという結果となった.また,(3)Olssonの方法による相関係数行列の推定は理論的整合性は高いが,計算所要時間はカテゴリ数,項目数の増加に伴い爆発的に増加するという特徴があるので,相関係数の方法を選択する際に注意を要する. 欠損値が因子分析法の適用に及ぼす影響 本章では,通常のデータ解析で実際に用いられていると考えられる欠損値の処理(因子分析をおこなう前処理)方式をとりあげ,シミュレーションによって比較をおこなった.取り上げた欠損値処理方式は中央値代入型,全削除型,項目対ごとの相関係数利用型の3種類であり,欠損の発生方式は,ランダム,特定因子に高く負荷する項目得点の和の大きさによる切断などの4種類である.その他の要因操作,評価基準等は前章の実験1とほぼ同じである. 欠損値が存在した場合には,ここで取り上げたどの処理方式を用いても,乖離指数は欠損なし条件と同程度の大きさにはならなかった.同様に,計算可能な回数も欠損値が存在する場合にはほとんどのケースで前章で得られた結果よりも悪くなっている.欠損値の処理方式に関しては,今回シミュレーションをおこなった条件内では観測可能な部分の中央値を代入して欠損のない状態のデータを作り上げた上で因子分析をおこなった場合に,乖離指数が小さく,計算可能な回数が多くなった. 本シミュレーションでもちいたデータの真の相関係数が比較的低かったためか,項目対ごとに相関係数を求めるという方法は,少なくとも全削除をおこなうよりは乖離指数が小さくなるという結果を得た.中央値代入条件には劣るものの,優劣の差はあまり大きくなかった. ベイズ的アプローチによる欠損値対策の提案 前章のシミュレーション結果から,欠損値が生じた場合に,利用可能な部分から相関係数を求めて因子分析法を適用するというのは悪くない方法であることが明らかになった.もしも,欠損データから相関係数を正確に求めることができるならば,欠損値が生じた場合の因子分析方法として利用できる.そこで,ベイズ的手法を利用した欠損値対策の提案をおこなった. その際,利用したのはGibbs Samplingという数値的方法である.具体的には変数間の関係として回帰モデルを仮定し,各母数の条件付き事後分布から乱数を発生させることによって,同時分布の実現値を得るという方法を利用して相関係数の推定をおこなった. 結果として,適切な事前情報が利用可能な場合,本章で提案したベイズ的方法を適用することによって,従来より用いられている相関係数の修正方法と比較して正確な推定値を得られることが明らかとなった. 因子数決定基準の改良 前々章のシミュレーション過程で,BICは観測数が十分に多いときには正しい因子数を選択するが,そうでないときに最適因子数を過小評価するという問題点に当面した.そこで,BICの近似を改良した因子数決定基準NBICの提案をおこない,人工データおよび実データに適用した.人工データの生成条件は上記の実験2と同様であり,適用した実データはBig Five形容詞チェックリストである. 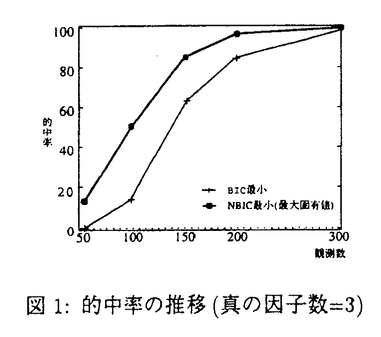 図1:的中率の推移(真の因子数=3) 図1:的中率の推移(真の因子数=3) 人工データに適用した結果を図1に示すが,新基準では観測数が少ない場合の因子数過小評価の問題が解決されている.また,実データに適用した場合には,観測数を50個から500個以上まで変化させても,比較的一貫して同一の因子数を選択するという結果が得られた. |
| 審査要旨 | | 本論文は,多変量解析の一種である因子分析の適用条件について幾つかの理論的な研究およびシミュレーション実験の結果をまとめ,因子分析に関する理論を深め,応用する際のガイドラインを得ようとしたものであり,全部で7章からなる. 第1章『序論』では本論文の目的と個々の研究の関連について説明している. 第2章『因子分析における初期値,解法が推定結果に及ぼす影響』では,共通性推定の初期値の違い,因子負荷量を求める方法の違いの因子負荷量の推定に対する影響についてシミュレーション実験をおこなっている.操作した要因は,共通性推定の初期値(SMC,1.0,他変数との相関の絶対値の最大値,0-1間の乱数の4種)と解を求める方法(アルファ因子分析,最尤法,主因子法,反復あり主因子,最小二乗法の5種),観測数(50,100,150,200,300の5種)である. 条件の組合せごとに100組ずつ,人工データを発生して因子分析法を適用し,因子負荷量行列の再現性(乖離指数),不適解の発生数等を評価基準として初期値の違いや各推定方法を比較考察した.その結果,(1)従来SMCは初期値として優れているとされてきたが,他変数との相関の絶対値の最大値を初期値とした場合と有意な違いは見られず,不適解の発生数は乱数条件を除く3種中最多であった,(2)最尤法は観測数が50のとき約30%の不適解を生じた,および,(3)推定が正しく収束した場合,初期値によって因子負荷量行列の再現性には違いがみられないなどの結果を得ている. 第3章『因子分析法の適用が不適切な条件の検討』では,質問紙調査における回答のように,順序性のあるカテゴリカルデータに対して適用した場合に生じる因子分析の問題点を明らかにするためにシミュレーション実験をおこなっている.人工データ生成の際操作した要因はカテゴリ数(2,3,5,7,カテゴリなし=連続値条件の5種),観測数(50,100,200,300の4種),項目数(15,30の2種),因子数(3,5の2種),データの度数分布型(均一型,負の歪み型,中央に山型,中央に谷型)のデータ特性と,相関係数の推定方法(簡便法,Olssonの方法)である.データ特性の組合せごとに100組ずつ人工データを発生し,2種類の方法で相関係数の推定をし,最尤法による因子分析を適用し,乖離指数,不適解の発生,AICやBICによる因子数の的中回数を規準として評価した. 結果として,シミュレーションをおこなった条件内で因子分析の適用に注意を要すると考えられるケースについて(1)カテゴリ数が少ない場合,(2)項目数が少ない場合,(3)(真の)因子数が多い場合,(4)観測数が少ない場合の4点に要約している.相関係数の推定方法に関しては(1)因子負荷量の再現性には違いが見られない,(2)Olssonの方法は計算不能回数が数倍多いという結果を得ている.Olssonの方法による相関係数行列の推定の計算所要時間はカテゴリ数,項目数の増加に伴い爆発的に増加するという特徴があり,観測数が少ない場合には推奨できないとしている. 第4章『欠損値が因子分析法の適用に及ぼす影響』では通常のデータ解析で実際に用いられていると考えられる3種類の欠損値の処理(因子分析をおこなう前処理)方式(中央値代入型,全削除型,項目対ごとの相関係数利用型)をとりあげ,シミュレーションによって比較をおこなっている.欠損の発生方式はランダム,特定因子に高く負荷する項目得点の和の大きさによる切断などの4種類であり,その他の要因操作,評価基準等は第3章と同様であった. 結果として,欠損値が存在した場合には,上記のどの方式を用いても完全な欠損値処理をおこなうことは出来ないという結果を得ている.欠損値の処理方式の比較に関しては,観測可能な部分の中央値を代入して欠損のない状態のデータを作り上げた上で因子分析をおこなった場合に,乖離指数が小さく,計算可能な回数が多くなった.またデータの真の相関が低い場合,項目対ごとに相関係数を求めるという方法は中央値代入条件よりわずかに劣るものの,全削除をおこなうよりは適切な処理方式であるという結果を得ている. 第5章『ベイズ的アプローチによる欠損値対策の提案』では,第4章のシミュレーション結果をふまえて,欠損データから相関係数を正確に推定する方法の提案をおこなっている。つまり,相関係数を正しく推定する事によって欠損値が生じた場合の因子分析を適切に実施出来るという観点からベイズ的手法を利用した欠損値対策の提案をおこなった.変数間の関係として回帰モデルを仮定し,各母数の条件付き事後分布から乱数を発生させることによって,同時分布の実現値を得るというギブスサンブリング法を利用して相関係数の推定をおこなっている. 結果として,適切な事前情報が利用可能な場合にはベイズ的方法を適用することによって,従来用いられている相関係数の修正方法と比較してより正確な推定値を得られることを明らかにしている. 第6章『因子数決定基準の改良』では,観測数が少ない場合のBICの的中率改善をおこなっている.第3章のシミュレーションにおいて,BICは観測数が少ないときに最適因子数を過小評価するという問題点を指摘しているが,本章ではBICの近似を改良した因子数決定基準NBICの提案をおこない,人工データおよび実データに適用している.人工データの生成条件は第3章と同様である. 人工データに適用した結果,新基準では観測数が少ない場合の因子数過小評価の問題が解決されている.実データとしては,5因子構造が普遍的に見られる性格形容詞のチェックリストを用いているが,観測数を50個から500個以上まで変化させても,比較的一貫して同一の因子数を選択するという結果を得ている. 第7章は結論である. これらの成果により,本論文は博士(学術)の学位に値するものであると審査員全員で判定した.なお,第2章は学術誌に論文として掲載済,第5章,第6章も投稿予定である. |