学位論文要旨
| No | 113167 | |
| 著者(漢字) | 成見,哲 | |
| 著者(英字) | Narumi,Tetsu | |
| 著者(カナ) | ナルミ,テツ | |
| 標題(和) | 分子動力学シミュレーション専用計算機の開発 | |
| 標題(洋) | Special-Purpose Computer for Molecular Dynamics Simulations | |
| 報告番号 | 113167 | |
| 報告番号 | 甲13167 | |
| 学位授与日 | 1998.03.30 | |
| 学位種別 | 課程博士 | |
| 学位種類 | 博士(学術) | |
| 学位記番号 | 博総合第165号 | |
| 研究科 | 総合文化研究科 | |
| 専攻 | ||
| 論文審査委員 | ||
| 内容要旨 | 本論文では、分子動力学シミュレーションを超高速に計算する専用計算機のシステムデザインを行った。 分子動力学シミュレーションはタンパク質の構造解析、固体物性の解析などを計算機上で行うための計算手法の一つで、非常に多くの分野で使われている。これは分子動力学シミュレーションが分子レベルのミクロな現象やそのダイナミクスについての多くの情報を提供してくれるためである。これらの情報は実験などのマクロな解析では得ることの出来ないものも多い。近年では生体高分子、特にタンパク質や核酸(DNA/RNA)の立体構造やそのフォールディング(直線的な分子が巻きとられて三次元的な立体構造をとる過程)に関する研究のために使われることも多い。タンパク質や核酸の立体構造は生体内のほとんどの機能(例えば免疫反応など)の基礎となるものであり、その解明は現在の生化学の大きな目標である。しかし現状では、X線結晶解析や核磁気共鳴(NMR)などの実験によって得ることの出来るタンパク質の立体構造は限られている。例えば大きな分子量のタンパク質やRNAなどは実験によって立体構造を求めることは難しい。さらにこれらの実験で得られる情報はフォールディングの機構を解明するには時間分解能が足りない。このため分子動力学シミュレーションはタンパク質や核酸の立体構造とフォールディング機構の解明のためには不可欠の手法である。 しかし、分子動力学シミュレーションにも大きなボトルネックがある。それは、この方法では原子に働く力を他の原子からの寄与を全て考慮に入れて計算するため、計算時間が膨大にかかりあまりたくさんの原子を入れたシミュレーションが出来ないという問題である。そこで筆者は力の計算部分だけを高速に計算する計算速度100Tflopsの超高速専用計算機を開発してこの問題を解消することを考えた。力の部分だけを計算する専用計算機を開発するというアプローチは、既に東大総合文化研究科の杉本らによって成功を収め、彼らは1995年に当時の世界最高速(1Tflops)の計算機(GRAPE-4)を開発した。筆者はこの研究を元にして分子動力学計算を高速化する計算機MDM(Molecular Dynamics Machine)のシステムデザインを行った。具体的にはGRAPE-4が重力多体問題専用計算機であったため、分子動力学計算を行えるように改良し、計算速度をさらに100倍の100Tflopsを目指す。MDMを用いて計算すれば10万原規模のタンパク質と周りの数十万の水分子を含んだ100万原子のシミュレーションを106ステップ(約1nsecのシミュレーション)行うのにほぼ一日しか要しない。これは50Gflopsのスーパーコンピュータで計算したとすれば何年もかかる計算である。以下ではMDMの具体的な設計について述べる。 まず、MDMの対象とする計算は100万原子を含んだ周期的境界条件下の古典的分子動力学計算である。クーロン力についてはカットオフをしない。これはカットオフによる誤差がかなり大きいことが近年報告されているからである。筆者はMDMの設計に関して以下のことを行った。 超高速の計算速度を実現するために計算の核となる部分については新たに二つのLSI(MDGRAPE-2チップとWINE-2チップ)を開発する。両チップとも現在の高速の汎用CPUの数十倍の計算速度が得られる予定である。 まず、MDGRAPE-2チップの仕様を決定した。これはMD-GRAPEチップ(Taiji et al.,1994)を改良したものである。主な改良点は、1)2原子間の力を計算するpipeline unitを1個から4個に増やす、2)分子間力計算の時に使う原子種ペア毎の係数をchipに内蔵する、3)一定半径より近い近接原子の情報を保管するメモリを内蔵する、4)内部動作周波数を3倍の100MHzにする、である。これらの改良でMD-GRAPEチップの12倍の計算速度を得ることが出来る。現在MDGRAPE-2チップは、理化学研究所、IBMが共同で詳細設計中であり、1998年夏にサンプルチップが出荷予定である。 次に、WINE-2チップの仕様を決定し、詳細設計を行った。WINE-2チップはMD-GRAPEチップのEwaldモ-ドを改良したものである。主な改良点は、1)離散フーリエ変換または離散逆フーリエ変換を計算するpipeline unitを1個から8個に増やす、2)pipeline unit内にsinとcosの計算ユニットをどちらかではなく両方持つ、3)pipeline unit内での計算精度を有効数字7桁から4.5桁に減らす、4)内部動作周波数を2.3倍の80MHzにする、である。これらの改良により、分子動力学シミュレーションで必要な計算精度を損なうことなくMD-GRAPEチップに対して約50倍の計算速度を得ることが出来る。現在WINE-2チップの詳細設計は終り、1998年2月のサンプルチップの出荷待ちである。 MDGRAPE-2チップ10個、WINE-2チップ16個をそれぞれ搭載するMDGRAPE-2ボード、WINE-2ボードの概念設計を行った。これらのボードはワークステーションなどのホストコンピュータに接続してバックエンドプロセッサとして動作する。基本的なボードの構成はMD-GRAPEボード(Fukushige et al.,1996)と変わらない。ただし、計算機と接続するためのインターフェイス部分にVMEバスではなく、PCIバスを使用する。これは現在PCIバスが、パーソナルコンピュータからスーパーコンピュータにまで普及している(しつつある)からである。つまりPCIバス規格のカードであればパソコンからスーパーコンピュータにまでシームレスに接続できる。 100Tflopsの計算速度を実現するにはMDGRAPE-2チップ、WINE-2チップがそれぞれ3000個程度必要である。しかしこれらのチップを効率良く動作させなければ実効的な計算速度は悪くなってしまう。シミュレーション空間内の原子に働く力をどのように並列処理すれば、計算効率がよく、必要な通信量を減らせるかを検討した。その結果、シミュレーション空間を格子状のセルに切り、そのセルを二つの階層に分けて領域分けし、それぞれの領域をハードウェアの階層に合わせてうまく配分すれば効率よくかつ通信量も減らせることが分かった。実際にはまず空間全体を8個の領域に分けそれぞれをnode(ワークステーションと専用ハードウェアのセット)が担当し、その領域を更に8個の小領域に分割しnodeの中にあるcluster(ボード複数枚とPCIバス一本を備えたもの)が担当する。このようにすればnode間やcluster間の通信が少なくて済む。 全体として、ホストコンピュータにはピーク性能50Gflopsのワークステーションクラスターを用いる、ワークステーションクラスターの合計88本のPCIバスに、合計256枚のMDGRAPE-2ボード、合計192枚のWINE-2ボードを接続する、という構成になる。このときMDGRAPE-2チップ、WINE-2チップはそれぞれ合計2560個、3072個使う。このシステム構成のもとで、ワークステーションクラスタでの計算時間、MDGRAPE-2チップとWINE-2チップの計算時間、ホストコンピュータとボードとの間の通信時間、ワークステーションクラスタ間の通信時間を見積もると図1、2のようになった。100万原子のシミュレーションを一日で106タイムステップ計算するには一ステップを0.1秒で終えなければならない。Ewald法のtruncation error( MDMの完成予定は1999年である。1999年の世界最高速のスーパーコンピュータはピーク性能で4Tflops程度と思われる。MDMは完成時には世界一の計算速度を誇るものになるであろう。図3は原子数に対して分子動力学計算で追うことの出来る時間(タイムスパン)を示している。これからわかるように、現在の最高速のスーパーコンピュータ上で分子動力学シミュレーションのプログラムを一週間動かし続けたとしても百万原子のシミュレーションは100psec程度までしか行えない。これはピーク性能が出たとした場合であり、実際には更にタイムスパンは短くなる。一方MDMを使うと、実効性能で見積もってもその30倍の3nsecまで計算することが出来る。 以上のように超高速の計算速度が見込まれる分子動力学計算専用計算機MDMは、タンパク質の3次元構造解析の分野など、分子動力学シミュレーションの世界に大きなブレイクスルーをもたらすと思われる。筆者はこのMDMのハードウェアの主要な部分について設計した。  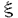 )が10-3の時。破線は=10-5の時。 )が10-3の時。破線は=10-5の時。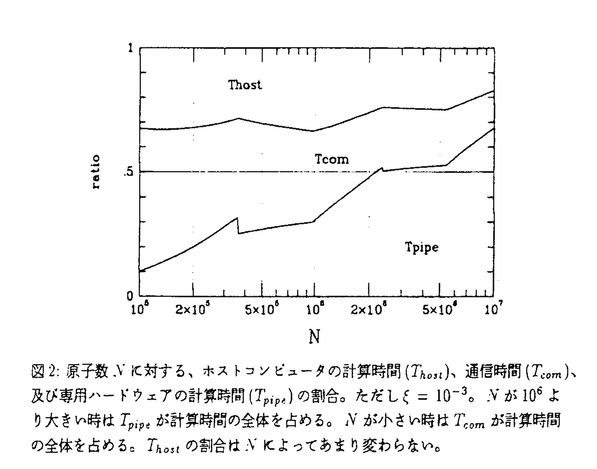 =10-3。Nが106より大きい時はTpipeが計算時間の全体を占める。Nが小さい時はTcomが計算時間の全体を占める。Thostの割合はNによってあまり変わらない。 =10-3。Nが106より大きい時はTpipeが計算時間の全体を占める。Nが小さい時はTcomが計算時間の全体を占める。Thostの割合はNによってあまり変わらない。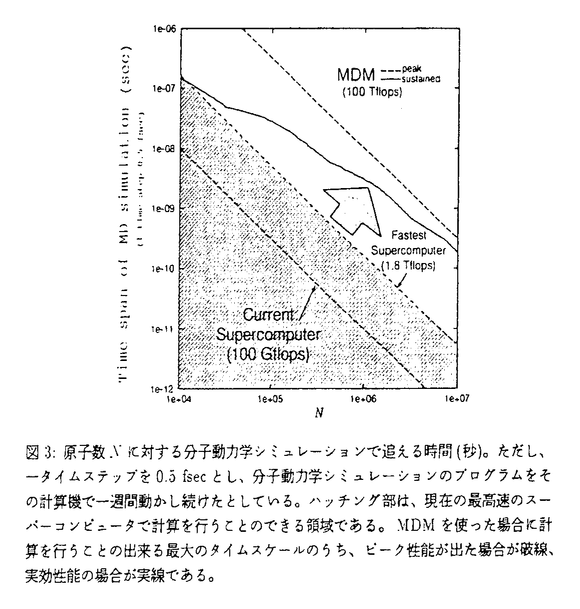 | |
| 審査要旨 | 本論文では、分子動力学シミュレーション専用計算機の設計を行い、これまで誰も行えなかった大規模な分子動力学シミュレーションが、実現可能な計算機の詳細な構成を初めて示したと認められる。 分子動力学シミュレーションは、たんぱく質や核酸、生体膜などの生命に関係する物質の働き、結晶の構造、過飽和気体からの核生成の様子などの研究に広く使われており、なくてはならない研究手法になっている。しかし、分子動力学計算に必要な計算時間が膨大で、その潜在力を生かしきれていない。その原因は、クーロン力や分子間力などのいわゆる非結合力の計算にあるので、重力多体問題専用計算機GRAPEと同様に、これらの力の計算だけを大幅に加速する専用計算機を作れば、この計算時間の問題を大幅に緩和できる。しかしこれまでは、その当時の世界最高速のスーパーコンピュータを越えるような演算性能を持った分子動力学シミュレーション専用計算機は、開発されていない。それに対し本論文では、完成時において世界最高速のコンピュータの20〜30倍の性能(100Tflops)が見込まれる分子動力学シミュレーション専用計算機(Molecular Dynamics Machine:MDM)の設計をして、これまで誰も出来なかった大規模な分子動力学シミュレーション(100万粒子で6×106step)が、実現可能であることを示している。本論文では、特に専用計算機MDMの心臓部となる演算用LSI(MDGRAPE-2とWINE-2チップ)の詳細な構成が述べられており、分子動力学計算を加速する計算機に関して新たな知見をもたらすものといえる。さらに、本論文で詳細な構成が提案された分子動力学シミュレーション専用計算機MDMは、X線結晶解析などの実験から求められた大規模なタンパク質およびその複合体(原子数で数万〜10万)の立体構造の分子動力学シミュレーションによる解析などに役立つと考えられる。 本論文は7つの章からなる。第1章では、分子動力学シミュレーションの有用性を示し、100万個の原子の系についての数ナノ秒にわたるシミュレーションを行えば、たんぱく工学や構造生物学、物性物理学に大きなブレークスルーを呼ぶ可能性が高いことを述べている。これまで、重力多体問題専用計算機GRAPE-4が、重力多体問題シミュレーションにおいて当時の最高速のスーパーコンピュータを上回る性能を出したことから、分子動力学シミュレーションも専用計算機で飛躍的に加速できることが論じられる。100万原子の数ナノ秒の分子動力学シミュレーションには現在の最高速(1.8Tflops)のスーパーコンピュータでも一年近くかかり、専用計算機で加速する必要があると結論している。 第2章では、後の章の準備のために、分子動力学シミュレーションの基本式などが記述されている。分子動力学シミュレーションでは原子は、古典的な粒子として取り扱う。各原子には、結合力(電子の量子力学的効果に起因する化学結合)と非結合力(分子間力、クーロン力)が働き、結合力は古典的なバネで近似する。計算量の多いのは非結合力であることから、専用計算機が非結合力のみを計算することにしている。また周期的境界条件を課したときにクーロン力をエワルド法にしたがって波数空間部と実空間部の二つに分けて計算することにしているた。 第3章では、分子動力学シミュレーション専用計算機MDMの構造が記述され、心臓部となる二つのLSIがどのような方針で設計されているかが述べられている。MDMは、ノード計算機と二つの専用計算機(MDGRAPE-2とWINE-2)とで構成されるノードがいくつも集まったもので、ノード間はスイッチによって接続されている。MDGRAPE-2及びWINE-2は複数のクラスターからなり、一つのクラスターはPCIバスによってノード計算機に接続される。クラスターは複数枚のボードからなり、ボード上にはMDGRAPE-2もしくはWINE-2チップが複数個搭載される、としている。 論文提出者は、チップの設計の出発点となったMD-GRAPEチップを概観し、MD-GRAPEチップの精度がクーロン力の波数空間部の計算に関しては不必要に高いことから、クーロン力の波数空間部の計算だけを行うWINE-2チップと、クーロン力の実空間部と分子間力を計算するMDGRAPE-2チップとの二つを作ることにした。この結果、WINE-2チップでは、各計算ステップにおける計算精度を減らすことでトランジスタ数を減らし、より速いクロック速度で動作するように設計できた。波数空間部の計算だけを独立させるという新しいアイデアによって、MDMの100Tflopsという超高速の計算速度が実現できると結論している。 また、論文提出者は、LSIの使用効率を見積もるために、たんぱく質分子の分子動力学シミュレーションを行う場合の必要な原子の種類の頻度分布を調べている。この分布のもとで分子間力の計算を多数のMDGRAPE-2チップで並列に実行する場合、そのための原子種テーブル用のRAMを10個以上のチップで共有すると実効的な性能が11%以下にまで低下することから、このRAMをMDGRAPE-2チップ内に納める必要があると結論している。この結果、分子間力計算の効率が92%にまで高まると予想されることから、このRAMを内蔵するという新しいアイデアはMDMの性能向上に非常に役立っていると考えられる。 第4章ではWINE-2チップの詳細な仕様と誤差の評価が記述されている。このLSIは、クーロン力の計算に必要な離散フーリエ変換およびその逆離散フーリエ変換を流れ作業で実行するパイプラインを8本持っている。一つのパイプラインは、Data Selector Unit、Inner Product Unit、Function Evaluator Unit、Accumulator Unitからなる。論文提出者は、三角関数を計算するFunction Evaluator Unitを二つ持つようにする、三角関数を評価する直前に位相を加えられるようにする、二つの波数について同時に足し合わせるようにする、という三つの新しいアイデアを用いて、離散フーリエ変換およびその逆離散フーリエ変換についての性能を向上している。これらの新しいアイデアによって、MD-GRAPEチップと同程度のテクノロジとトランジスタ数で、MD-GRAPEチップに対して約50倍の性能向上が期待できる、としている。 さらに、論文提出者はWINE-2チップの動作をビット単位で再現するソフトウエアシミュレータを作り、力の積算値で4.5桁の相対精度を保証するという設計方針が正しく実装されていることを確認している。また、それを使っていくつかの場合について、分子動力学シミュレーションを実施し、64ビット浮動小数点で計算した場合との差は、十分に小さいことを示している。 第5章では、MDGRAPE-2チップの詳細な仕様と誤差の評価が記述されている。このLSIはクーロン力の実空間部と分子間力の計算を行うパイプラインを4本と、分子間力の計算に必要な係数の値を格納するためのRAMを持っている。この結果、MDGRAPE-2チップがこれまでのチップの12倍の性能向上が期待できる、としている。 第6章では、MDM全体の性能が予測されている。ノード間通信速度やPCIを通じたボードとの通信速度などを仮定した上で、分子動力学シミュレーションにおいて、専用計算機の計算時間、ノード計算機の計算時間、ノード間およびノードコンピュータと専用計算機の間の通信時間を見積っている。その結果、ホスト計算機に8ノード程度のワークステーションクラスタ、MDGRAPE-2チップを2560個、そしてWINE-2チップを3072個使えば、百万個の原子を含む系の数ナノ秒にわたる分子動力学シュミレーションを一週間で終えることが達成できると予測している。 第7章はディスカッションの章で、他の専用計算機やスーパーコンピュータとMDMとの比較、将来への発展性、高速アルゴリズムの実装の可能性、および、MDMの分子動力学シミュレーション以外の応用の可能性が議論されている。 まとめると、論文提出者は、これまで誰も行えなかった大規模な分子動力学シミュレーションを可能にする専用計算機MDMを提案し、その具体的な設計を初めて示している。クーロン力の波数空間部専用のLSIを開発すること、分子間力係数用のRAMを内蔵することなどの新しいアイデアによってのみこのMDMの計算性能が達成できると考えられる。このように論文提出者は、分子動力学シミュレーションの分野で重要な新しい知見を与えている。よって、本論文は博士(学術)の学位請求論文として合格と認められる。 | |
| UTokyo Repositoryリンク | http://hdl.handle.net/2261/54611 |