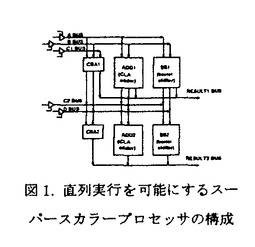
本論文は大規模集積情報処理システムの高性能化および高機能化に関するもので、本文9章からなる。 第1章は序論であって、今後達成の予想されるマイクロプロセッサを中心とした情報処理システムの大規模化を述べるとともに、従来行われてきた高性能化手法に関する問題点を述べ、これを克服するために新しいアーキテクチャや、ニューロプロセッサのような新しいアプローチの研究が必要であることを論じている。 第2章は、「直列実行機構を有するマイクロプロセッサアーキテクチャ」に関する研究成果を述べたもので、既存のスーパースカラ機構にCSA(桁上げ保存加算器)を導入してデータパスを構成したプロセッサの試作を述べ、直列実行機構を容易に導入する手法及び演算器の制御法を示している。また、CSAを多段に接続し、複数の命令を多直列に演算する機能を付加した乗算器の構成を提案し、同演算器が従来の乗算器と比して少ないコストで導入可能であることを示している。 更に第3章において、「直列実行機構を有するALUの最適設計」に関する研究成果を述べ、直列演算時のレイテンシの伸長を抑えた直列実行ALUの回路構成を提案している。同ALUは、既存のスーパスカラ機構に容易に導入することが可能で、16.6%のレイテンシの伸長で直列実行機構が導入し得ることを示している。同ALUを用いてプロセッサを設計することで、動作周波数を低くして演算性能を向上させ、消費電力あたりの演算性能を向上させることが可能となることを論じている。 第4章は、「冗長2進演算を利用したマイクロプロセッサアーキテクチャ」に関する研究成果を述べたもので、ALUの入力部に4:2コンプレッサを導入し、桁上げ保存信号の入力を可能とするとともに、4:2コンプレッサ部の演算時間でパイプライン化することにより、実行パイプラインのレイテンシを短縮することを可能とする機構をはじめて提案している。また、従来のスーパパイプライン機構と比較してデータ依存によるストール確率が軽減されることを示している。さらに、同手法を用いたマイクロプロセッサの試作を行い、同機構をマイクロプロセッサに導入する際に必要となるデータパスの構成法やその制御法を明らかにしている。 第5章は、「ロードアドレス予測機構」に関する研究成果を述べたもので、ロード命令の命令アドレスをタグとし、前回アクセスしたデータアドレスを保持するロード命令キャッシュを導入し、命令のデコードと同時にデータキャッシュをアクセスする機構により、ロード命令のレイテンシを削減することを可能とする概念を提案している。更に、同機構をマイクロプロセッサに適用することにより削減されるサイクル数の予測を行い、性能向上に有意な効果が認められることを示している。 第6章は、「時間多重化空間多重化の併用によるディジタルニューロプロセッサの高性能化」に関する研究成果について述べたもので、1ビット全加算器を基本演算要素とし、レイテンシを短縮するとともに集積数を向上して、単位面積あたりの演算能力が14.4GCPSに達するニューロプロセッサの試作例を示している。また、同時に消費電力の増大についても述べ、消費電力及び回路遅延の両面からの最適設計が重要であることを論じている。 第7章は、「カオス現象を利用した機能回路」と題し、これまでに述べたディジタル回路のみでは実現し難い用途を補完するための機能回路の実現例として、集積回路中のカオス現象を用いたノイズ生成回路を提案し、確率分布の均等なノイズ値を生成することを示したのち、集積回路による実装例を示している。 更に第8章にて、「カオス現象の発生機構の定量解析」に関する研究成果を述べ、本研究で新たに見出されたカオス生成回路の特性を定量的に解析し、測定結果と良好な一致を得る解析式を提示して、前章のカオス集積回路を設計するためのデバイスモデルを明らかにしている。 第9章は結論であって、第2章から第8章で得られた成果を要約し、提案された各種機構の特徴からそれぞれが適する分野を論じて、本研究で提案された各機構が大規模集積情報処理システムの高性能化あるいは高機能化の実現にあたって有用であることを示している。 以上のように本論文は、大規模集積情報処理システムの高性能化と高機能化を目的として、マイクロプロセッサのアーキテクチャに関し新しい提案を行ってそれを評価するとともに、その機能を補完するニューロプロセッサ、特にカオス生成素子について独創的な提案を行い、カオス生成回路の設計に用いるデバイスモデルを明らかにしたもので、電子情報工学上貢献するところが多大である。 よって本論文は博士(工学)の学位請求論文として合格と認められる。 |