本論文は「A Study on Robust Decision Rules in Automatic Speech Recognition」と題し、学習と認識での諸条件の異なりにより認識率が低下するという現在最も問題とされている課題に取り組み、従来の隠れマルコフモデルによる認識手法を見直すことによって、この様な異なりに頑健な新しい手法を開発したものであって、全7章からなり、英語で記述されている。 第1章は「Introduction」であって、本論文の背景と目的を述べている。まず、音声認識で問題となっている要因として、学習環境と認識環境の違いによる認識率の低下をあげ、それに対して行われている種々の問題設定とアプローチを例を挙げて概説している。その上で、本論文で取り扱う問題を、この様な違いを考慮した認識の決定理論であるとし、ベイズ予測分類とMinimax法に基づいて新しい方式を開発するとしている。さらに、本論文の各章の位置付けを述べている。 第2章は「Decision Rules for Speech Recognition and Their Robustness」と題して、まず、学習環境と認識環境の違いがある場合の決定理論としてのOptimal MAPを位置付け、違いについての知識が得られない場合に確率分布を近似したplug-in MAPとなることを示した上で、違いによる不確定性をモデル化する手法として、HMMパラメータの分布をモデル化するベイズ予測分類と、観測特徴ベクトルに対する認識単位の確率をモデル化するMinimax法を説明し、続く章の導入としている。 第3章は「Robust Speech Recognition Based on Bayesian Predictive Approach」と題して、ベイズ予測分類に基づく頑健な認識手法の提案を行っている。連続分布HMMの尤度関数は、本来、あらゆる状態経路と混合分布成分について総和を取って計算するが、これをそのままベイズ予測分類に用いると認識単位に対する観測特徴ベクトルの確率密度分布を計算することは困難である。尤度最大の経路と分布で代表させるViterbi手法を適用することによってこれを可能とするViterbi Bayesian Predictive Classification(VBPC)を提案し、それを反復的に計算するアルゴリズムを開発した。また、連続分布HMMの混合分布成分を直接ベイズ予測密度によって推定し、MAP決定規則を利用するBP-MC法を提案した。次に、提案手法の評価のために、環境の違いを白色雑音とした場合の認識実験を孤立数字音声と連続数字音声とについて行い、VBPCとBP-MCがPlug-in MAP法に比較して優れていることを示している。さらに、不確定性によるモデルパラメータの分布の範囲と認識性能との関係を調べ、比較的分布によらない結果が得られるとしている。環境の違いとして種々の実環境下雑音、性差を考慮した認識実験も行い、同様に提案手法が有効ではあるものの、その程度は低下するとしている。これは、違いに特徴があるためであると考察し、次章の学習の必要性を指摘している。 第4章は「Improviog Viterbi Bayesian Predictive Classification via Sequential Bayesian Learning」と題して、環境の違いによるHMMパラメータの変動の事前確率分布を正規分布の集合として近似し、認識環境データ毎にそれを推定し直す手法を開発した上で、VBPCの決定理論に組込んでいる。推定の際に、分布の数がべき乗で増大するため、通常では計算時間が爆発してしまうが、これを避けるために、各推定毎に認識に有効な分布を選択する手法を開発している。環境の違いが白色雑音あるいは性差である場合について数字音声の認識実験を行い、Plug-in MAPで適応を行った場合と比較し、その有効性を示している。選択する分布の数についても言及し、違いに特徴がある性差のような場合には分布の数がある程度必要との結論を得ている。 第5章は「Minimax Search for Robust Continuous Speech Recognition」と題して、Minimax法に関する2つの先行研究を紹介した上で、連続音声への拡張が困難と言う問題点があることを指摘している。これに対し、Viterbiサーチを行うことで、反復的な最適経路探索アルゴリズムを開発し、連続音声への拡張が可能であるとしている。白色雑音付加の場合の離散数字音声について有効性を示すとともに、連続数字音声の認識実験でPlag-in MAPに対する優位性を示している。 第6章は「A Comparative Study with Other Robust Methods」と題して、環境の違いに対処する種々の手法との性能比較を行っている。具体的には、違いを特徴量空間あるいはモデル空間で考慮するStochastic Matching、HMMパラメータの個々のパラメータの広がりを正規分布で近似するQuasi Bayesian Predictive Classification、第5章での2つのMinimax手法等との比較を、白色雑音付加と性差の場合について行い、提案方式の有効性を示している。また、特徴量レベルでの違いの補償としてCepstral Mean Normalizationを行った場合にも同様に有効であるとしている。 第7章は「Conclusions」であって、本研究で得られた成果を要約し、将来の課題について言及している。特に、BPCにおける事前確率密度の適切な予測、あるいはMinimax法における不確定な近傍の適切な予測が重要であるとしている。 以上を要するに、本論文は、認識環境が学習環境と異なる場合にも有効な認識決定理論の実現可能な定式化を示し、それをもとに頑健な認識手法を開発したものであって、電子工学、情報工学に貢献するところが少なくない。 よって、本論文は博士(工学)の学位請求論文として合格と認められる。 |  、事前確率密度分布(pdf)p(
、事前確率密度分布(pdf)p(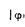 ,W)、ハイパーパラメータ
,W)、ハイパーパラメータ

 (
(


