| 内容要旨 | | 本論文は組織学習(organizational learning)の概念を計算論的な視点で整理して,マルチエージェントによる一つの組織学習モデルを提案し,いくつかの工学的問題を通してその有効性を示すものである. 近年,ネットワークの拡大や並列計算機の身近な利用により分散環境における方法論が要求されている.群知能ロボット(swarm intelligent robots)の分野でも,マルチロボットによるフォールトトレランスや高度な協調作業の実現が求められるようになってきた.しかし,このような分散環境やマルチロボット(エージェント)環境では様々なレベルや種類の学習が考えられるが,それぞれが相互に影響しあうため,従来の研究ではある一つの学習に絞ったものが多い.そのため,複合的に捉えた研究はほとんどなく,これらの学習の統合の効果も不明確であり,学習のレベルや種類も整理されていないのが現状である. そこで,本稿ではこれらの学習を単独ではなく統合的に扱う組織学習に焦点を当て,その効果と学習のレベルや種類を整理する.この学習は社会科学における組織論の分野で盛んに研究が行われ,一般的には"組織のパフォーマンスや能力を向上させる学習"と定義されている.しかし,個体学習と組織学習の本質的な違いや,各個体の学習目標を組織全体の目的から適切にブレイクダウンする方法論が明確ではなく,計算論的なモデルとして構築することには直接的につながっていない.このような背景から,本稿では組織学習の概念を整理し,その概念を取り入れた一つの計算論的モデルである組織学習指向型分類子システム(Organizational-learning oriented Classifier System:OCS)を構築する.このモデルはマルチエージェントベースの学習モデルであり,学習機能としては(a)強化学習(reinforcement learning)メカニズム,(b)ルール生成メカニズム,(c)ルール交換メカニズム,(d)組織知識の生成/利用メカニズムの四つを複合して保持している.その中でも(a)は各エージェントが明示的でかつ大域的なコントロールなしに適切な機能を獲得すること,(b)は新たにルールを生成することによって動的な環境に適応することに貢献する.組織内コミュニケーションの一つである(c)はエージェント間でルールを交換することによって組織全体のパフォーマンスを向上させる.さらに(d)は解の改善だけでなく問題を解くための施行回数を減らすことにも貢献する.特に本モデルにおける(d)の組織知識は分業方法に関する知識のことを意味する.また,これらの(a)〜(d)はそれぞれ社会科学の組織論で議論されている組織学習の個体のシングル/ダブルループ学習,組織のシングル/ダブルループ学習と同じ働きをする.さらにこのような学習の統合は各々のレベルや種類の学習の欠点を補うだけでなく,学習間の相互作用を可能にし,単一の学習の和以上の効果を導く可能性を秘めている. 具体的なアーキテクチャとしては,明示的かつ大域的にエージェントをコントロール/評価するのではなく,図1に示すように各エージェントが次の五つの要素で構成される局所的評価メカニズム(local evaluation mechanism)を用いて行動する:(1)個体間で共有する分業方法に関する組織知識を記憶するメモリ,(2)個体知識を蓄えるLCS(Learning Classifier System)のプロダクショシシステム(if thenルールの集合),(3)環境(environment)の状態(state)の認識結果を蓄えるメモリ(WM:working memory),(4)選択されたルールを順番に記憶するメモリ,(5)一連の記憶されたルールに対する評価メカニズム.また,このモデルでは全体の情報を獲得することはできない一般的な現実問題を対象としているため,各エージェントは部分的な環境情報のみに基づいて個体知識のルールを選択し,そのルールに記述された一つの行動をとる.さらに各々の判断基準(局所評価関数)にしたがって自己の行動を評価する.各エージェントはこのような自己評価のサイクルを通してルールの生成削除と適用戦略の学習を同時に行い,組織全体のパフォーマンス向上に貢献する機能を獲得する.そして最終的に各エージェントがそれぞれ適切な機能を獲得したとき,この機能分化が与えられた問題を効果的に解く分業方法になる. 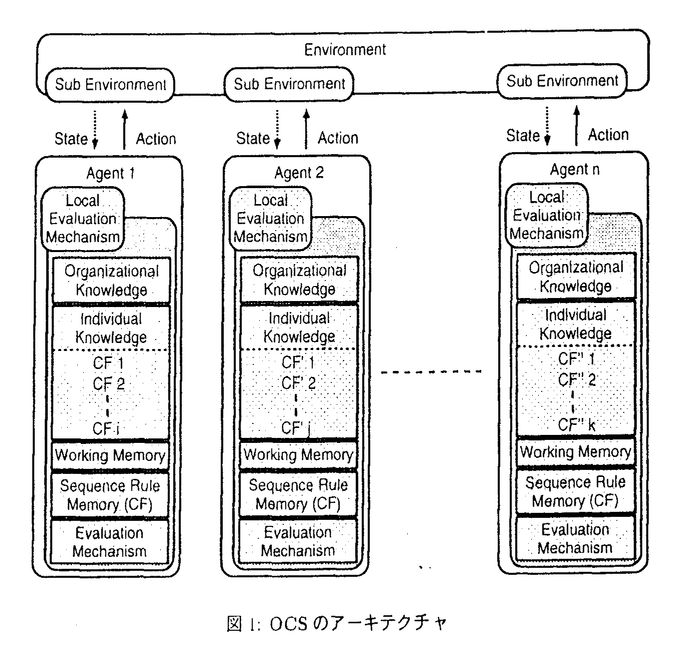 図1:OCSのアーキテクチャ 図1:OCSのアーキテクチャ さらに本稿では,工学的視点から本モデルにおける組織の問題解決能力を向上させるために,(1)組織学習のためのマルチエージェント強化学習法,(2)組織知識の利用法の二つの改善法を提案する.特に(1)の場合,次の三つの問題に焦点を当てる.(1-1)従来の強化学習法では時間さえかければ最終的には与えられたタスクを達成できるという前提が多く,実問題に多く存在するデッドロックを考慮したものは少ない.特にマルチエージェント環境ではエージェント数の増加にともない,デッドロックに陥る可能性が高くなるため,これらの問題に対処する強化学習法を提案する.(1-2)タスク変更が頻繁に起こる宇宙作業に本モデルを応用した場合,本モデルは与えられたタスクによって異なる大きさの状態空間を必要とする.そのため,あらゆるタスクを想定して大容量のメモリを宇宙ロボットに積む必要があり,不必要なコストがかかる.そこで,状態空間の大きさ固定の強化学習法を提案する.(1-3)マルチエージェント学習では,あるエージェントの行動が他のエージェントの学習にも影響を与えるため,一般的には収束が保証されていない.また,解の達成度によって報酬の値が変わることも無いので,過度の強化が起こる可能性がある.そこでこれらの問題を解決する強化学習法を提案する.次に(2)の場合,以下の二つの問題について議論する.(2-1)マルチエージェント環境における知識の再利用を考えると,シングルエージェントに比べて局所解が数多く存在するため,蓄積された知識をいかに適切に利用して数多い局所解から最良解に近い解を見出すことが重要になる.そこで,フォーメーション,獲得された機能の選択,新たな機能の追加における組織知識の利用に関して考察する.さらに(2-2)マルチエージェント環境では局所解の数が多いことから,一般化された知識を求めることは困難である.そこで,ある局所解に特化した知識ではあるが,この知識を一括で利用する場合と段階的に利用する場合の効果について考察する. 実験では本モデルのアーキテクチャおよびさまざまな改善法の有効性を示すために,実規模のプリント基板(printed circuit board)における再設計問題と宇宙ロボットによるトラス組み立て問題に適用した.特に前者の問題は総配線長の短いレイアウトを求める問題であり,重なり状態の各部品が重なりを解消するように行動しながら,さらに総配線長が短くなるような配置を導く一連の行動を獲得することが目的となる.一方,後者の問題は梁を順番に組み立ててトラスを組み立てる問題であり,各ロボットが梁を握る,溶接するなどの行動を行いながら,デッドロックに陥らずにタスクを達成する一連の行動を獲得ことが目的となる.本稿ではこのような工学的問題に本モデルを適用し,シミュレーションした結果,次のような所見を得た. 1.OCSは専門家より短い配線長で与えられた部品を基板上に配置することができた.さらに図2に示す学習回数に対する総配線長の変化から分かるように(b)ルール生成メカニズムに(a)強化学習メカニズム,(c)ルール交換メカニズム,(d)組織知識の生成/利用メカニズムを一つずつ加えることによって,さらに短い総配線長を見出すことが可能になる.これは単独のメカニズムの限界を示すと同時に統合の効果を示している.なお,図2においてEXPERTは専門家,(a)〜(d)はそれぞれOCSの四つの学習メカニズムに対応する.  図2:施行回数ごとの総配線長 図2:施行回数ごとの総配線長 2.OCSは大域的に統制/評価することが困難な問題,適切なルールを事前に用意することが困難な問題,満たさなければならない項目が多い問題,ヒューリスティックな知識が十分でない領域に対して有効である. 3.本モデルにおけるマルチエージェント強化学習法は解の改善だけでなく,施行回数を減らすことにも貢献する.特にデッドロックを含む問題では図3に示すように4,8,16台のロボットが提案する強化学習法を用いることによって適切な機能を獲得し,デッドロックに陥らずにタスクを達成することが可能になった.この図においてWは溶接位置に移動し梁を溶接する行動,Bは梁組み立て位置に梁を移動する行動,Sはステーションに戻る行動を示し,例えば4台のうち2台のロボットは梁を運び,ステーションに戻ることを繰り返す機能を獲得したことを示す.また,FIFO(First In First Out)方式で強化対象ルールを蓄積することによって状態空間を固定するだけでなく,協調行動獲得を容易にし,さらに最良解の近傍で強化しない強化学習法を提案することによって,マルチエージェント学習の停止を実現し,他の問題への適応を困難にする過度の強化の除去も可能にした.また,シングルエージェントで合理性が保証されている強化方法とは逆の等比増大関数を用いて強化する方がマルチエージェント学習では効果的であることも確認した.  図3:ロボットの機能分化 図3:ロボットの機能分化 4.組織知識の転用は類似の問題を早く解くだけでなく,解を改善させることが可能になること,さらに新たな組織知識を生成するきっかけや組織知識なしでは解くことのできない問題を解く可能性を持っていることが分かった.また,これらの知識は組織全体の質をある程度決定すること,知識の一括利用よりも段階利用の方がさらに施行回数や解を改善することが実験的に確かめられた. 以上より,本稿では社会科学における組織論で議論されている組織学習の概念を計算論的な視点で整理し,その概念を取り入れた四つの学習メカニズムを持つOCSの提案とその有効性の検証を行った.さらにいくつかのOCSの改善方法を提案し,その効果を実規模のプリント基板における再設計問題と宇宙ロボットによるトラス組み立て問題を用いて示した.最後に,本稿で提案したOCSは今回取り扱った問題以外にもマルチエージェントシステムで形成されるさまざまな工学的な分野への応用が期待でき,計算論的な立場から社会科学における組織論に貢献することも可能だと考えられる. |
| 審査要旨 | | 工学修士 高玉圭樹 提出の論文は「マルチエージェントによる組織学習の方法に関する研究」と題し,全8章と付録からなっている. 近年,インターネットやマルチメディアの発展によるネットワークの拡大や並列計算機の身近な利用により分散環境における問題解決の方法論が注目され,群知能ロボットの分野でも,マルチロボットによるフォールトトレランスや高度な協調作業の実現が求められてきている.また一方では、大規模複雑問題を従来のような中央集権的視点で解くのではなく,マルチエージェントの視点で捉えることによって新しい知見が得られるようになってきた.このような分散環境やマルチエージェント環境における問題解決においては、様々なレベルや種類の学習が存在し,それぞれが相互に影響しあうにもかかわらず、従来ではある一種類の学習の適用に関する研究が多く、結果として適用範囲が限られ実問題にはなかなか応用できないのが実状であった.このような問題を解決するため、本論文では、社会科学における組織学習の概念を取り入れた、新しい統合的な計算論的学習モデルを構築し、実問題への適用を図っている.特に、複数の学習の統合により問題解決の能力の向上と適用範囲の拡大がなされることを主張し、それがどのようなメカニズムで起こるのかを詳細に検討している. 第1章は序論であり,本研究の背景を述べ,関連する研究の成果とその問題点を検討し,研究の目的と意義を明確にしている. 第2章では,社会科学における組織論の分野で盛んに研究されている組織学習の定義や従来のモデルについて言及している.続いて,組織学習におけるループ学習を計算論的視点で分類し,それを用いた一つの計算論的組織学習モデルの設計原理を提案し技術課題をまとめている. 第3章では,提案した設計原理に基づきながら,学習分類子システムに組織学習の概念を組み込み,一つの組織学習モデルとして組織学習指向型分類子システム(OCS:Organizational-learning oriented Classifier System)を提案している.このモデルはマルチエージェントベースの学習モデルであり,(1)強化学習,(2)ルール生成,(3)ルール交換,(4)分業方法利用の4つの学習メカニズムから構成されていることを述べている. 第4章では,提案したアーキテクチャの有効性を示すために、簡単な例題ではなく,2つの実際的でかつ工学的な問題を提起し,それぞれの問題の特性,OCSの設計法を説明している.2つの問題とは,実規模のプリント基板における再設計問題と宇宙ロボットによるトラス組み立ての作業分担問題であり、前者では、いかに効率的に配線長の短いパーツ配置を実現するかが要求され、後者では、デッドロックに陥らないような作業分担をいかに自律的に生成するかが問題であることを述べている. 第5章では,これらの問題を通して本学習モデルの有効性を示している.再設計問題に関しては,4つの学習の組合せである全15種類の実験を行い,その結果からそれぞれの学習の効果と本モデルの特性を考察している.続いて,群知能ロボットによるトラスの組み立て問題では,分業方法をあらわす組織知識の利用に関する学習に焦点をあて,その効果を検討している.さらに,本モデルの可能性と限界を議論し,他の関連研究との関係を組織論的および計算論的観点から述べている. 第6章では,本モデルの改善点として,マルチエージェント強化学習法と組織知識の利用法をとりあげ,いくつかの改善法の有効性を第4、5章と同じ問題を通して検証している. 第7章では,ペントミノ配置問題を通して、問題の規模が大きくなった場合の本モデルの能力の変化を従来のモデルやメカニズムと比較し、その違いの原因を考察している.特に、問題の規模が大きくなるほど、本モデルが従来法に比べて少ない計算量で良い解を得る傾向が高まることを示している. 第8章は結論であり,本研究において得られた結果を要約している. 付録はペントミノ問題の詳細とそれに対するOCSの設計法をまとめている. 以上要するに,本論文は社会科学における組織学習の概念を計算論的な視点で整理し,それに基づいたマルチエージェントによる一つの組織学習モデルを提案するとともに,学習の統合化によって従来の手法に比べ問題解決の能力と適用範囲が向上することを工学的な実問題を使って示したものであり、知能工学および情報工学上貢献するところが大きい. よって本論文は博士(工学)の学位請求論文として合格と認められる. |