近年の計算機技術の進歩により莫大な履歴データが蓄積され、それらを解析することが可能となった。大量に蓄積された履歴データを解析し、その中に埋もれた有用な情報を自動的に抽出するデータマイニングの研究が進められている。データマイニングで得られる情報の代表的なものとして、相関ルールがある。相関ルールは「商品AとBを購入した顧客は商品Cも同時に購入する」のような規則であり、小売業、医療、金融、不動産をはじめとする多くの業界で利用が開始され、盛んに研究されている。しかし、単純な相関ルールではデータベース中に現れるデータの組合せのみの解析であり、実際に利用する場合に十分な情報とは言えないものである。相関ルールを拡張し、更に詳細な解析を可能とした研究として、データの分類階層を考慮した一般化相関ルール、時間情報を導入した時系列パターンがある。これらの解析には、大規模なデータベースを繰り返し検索し、数多くの探索候補を調べる必要があり、その処理負荷が非常に高くなるため、並列処理による高速化が不可欠である。本論文では、時系列パターンと一般化相関ルール抽出処理の高速化を目的とした並列処理方式ならびに負荷分散手法を提案し、商用並列計算機および100台のパーソナルコンピュータから構成される大規模PCクラスタ上に当該手法を実装し性能評価を行った。 はじめに、時系列パターンに関して検討する。時系列パターンマイニングは時間軸に沿った解析を行うことにより時間の持つ意味を含むルールを抽出する手法である。時系列パターンを抽出するには属性の組合せだけではなく、属性の組合せの順列を調べなければならないため、その探索候補の数は相関ルール抽出の探索候補と比較して著しく大きくなる。 本論文では時系列パターン抽出の並列処理方式として、データベースをプロセッサ間に分散させることによるディスク入出力処理の並列化を行う手法(NPSPM方式:Non Partitioned Sequential Pattern Mining)、更に探索候補もプロセッサ間に分割して割り当てることにより記憶効率の向上を図る手法(SPSPM方式:Simply Partitioned Sequential Pattern Mining、HPSPM方式:Hash Partitioned Sequential Pattern Mining)を検討する。NPSPM方式は最も単純な並列化であるが、探索候補が単一プロセッサの主記憶から溢れる場合に処理性能が低下する。SPSPM方式とHPSPM方式は探索候補をプロセッサ間に分割して割り当てることにより、システム全体の主記憶空間を効果的に利用する。このように探索候補を分割した場合、処理にプロセッサ間のデータの相互通信が必要となる。SPSPM方式では探索候補を無作為にプロセッサ間に分割するため、データの放送が必要となり、各プロセッサがシステム全体のデータを処理するため処理性能が悪くなる。HPSPM方式ではハッシュ関数を用いて探索候補をプロセッサ間に分割する。これにより、データの放送を回避し、必要なデータを特定のプロセッサに送信することで処理が可能となる。また、すべてのデータに対する処理ではなく受信したデータのみを調べるため、処理負荷の削減が可能となる。 提案する並列処理方式の有効性を調べるために商用並列計算機上に実装することにより性能評価を行った。図1に最小支持度を変化させた場合の処理時間とプロセッサ台数を4台から16台まで変化させた場合の台数効果を示す。最小支持度が小さくなると探索候補数が増加する。NPSPM方式では探索候補が単一プロセッサの主記憶空間から溢れ、付加的なディスク入出力処理が生じるため、処理性能が急激に低下する。SPSPM方式はデータの放送が放送が必要なため、大量の通信が引き起こされる。更に各プロセッサがすべてのデータを処理することになるためCPU処理負荷が高くなり、良い性能が得られない。HPSPM方式は探索候補をハッシュ分割することによりディスク入出力処理負荷、通信処理負荷の低減を実現している。データの通信が必要となるため台数効果ではNPSPM方式に若干劣るものの、処理時間、台数効果共に良い性能を示している。 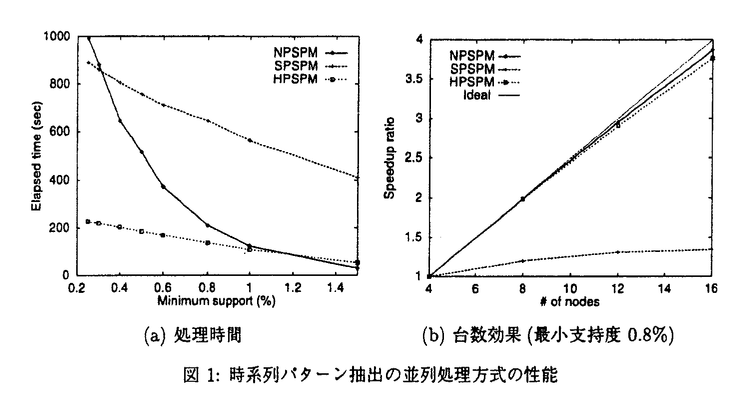 図1:時系列パターン抽出の並列処理方式の性能 図1:時系列パターン抽出の並列処理方式の性能 次に一般化相関ルールについて検討する。実際のデータはその特徴により分類階層構造化されている場合が多く、これを考慮することにより従来の単一階層の相関ルールマイニングでは抽出することができなかったルールを抽出することが可能となり、詳細なデータの解析が可能となる。このデータの分類階層を考慮した相関ルールが一般化相関ルールと呼ばれている。この場合も異なる分類階層間の属性の組合せを調べることになるため、探索候補数が非常に多くなり、データベース中に含まれるデータにデータの階層構造を付加して調べるため、その処理が複雑になる。 本論文では一般化相関ルール抽出の並列処理方式として、データベースをプロセッサ間に分散させることによるディスク入出力処理の並列化を図る手法(NPGM方式:Non Partitioned Generalized association rule Mining)、更に探索候補もプロセッサ間に分割して割り当てることにより記憶効率の向上を図る手法(HPGM方式:Hash Partitioned Gemeralized association rule Mining)、データの分類階層構造を考慮して探索候補の分割を行うことにより通信量の低減を図る手法(H-HPGM方式:Hierarchical HPGM)を検討する。NPGM方式も単純な並列化であるが、NPSPM方式と同様に探索候補が単一プロセッサから溢れた場合に処理性能が低下する。HPGM方式とH-HPGM方式では探索候補を分割してプロセッサ間に割り当てることにより、システム全体の主記憶空間を効果的に利用する。HPGM方式では探索候補がハッシュ関数を用いて分割されるが、一般化相関ルールマイニングでは単純にハッシュ関数を適用した場合、階層構造を含めたデータをプロセッサ間で相互通信する必要がある。そのため、HPGM方式では十分な性能を得ることが困難である。H-HPGM方式ではデータの分類階層を考慮し、データの分類階層の組み合わせを分割単位とし、これにハッシュ関数を適用することにより探索候補の分割を行う。これにより、プロセッサ間での階層構造の相互通信が不必要となり、通信量を抑えることが可能となる。 更に、プロセッサ間の負荷バランスを制御する手法を検討する。利用するシステムの並列度が上昇するに従い、プロセッサ間の負荷バランスを均等にすることが困難となる。本研究で提案するH-HPGM方式では一般化相関ルールマイニングの並列処理方式では、探索候補をデータの階層構造を考慮してプロセッサ間に分散させて割り当て、それぞれのプロセッサが割り当てられた探索候補に対する処理を行う。これにより、ディスク入出力処理、通信処理の負荷を低く抑えることが可能であるが、CPU処理負荷である探索候補を調べる処理の性能を改善することはできていない。データマイニングで扱うデータには偏りが存在するため、単純に探索候補の数をプロセッサ間に均等に割り当てることではCPU処理負荷の偏りが生じ、負荷の均衡化を実現することが困難である。本論文では一般化相関ルール抽出の並列処理方式の負荷分散手法として、データの統計情報を用いた探索候補分割の最適化手法(H-HPGM(flat+all))、支持度の高くなると予測される探索候補を複製する手法(H-HPGM-FGD:H-HPGM with Fine Grain Duplicate)を提案した。H-HPGM(flat+all)ではデータの統計情報から探索候補の支持度を予測し、探索候補の分割粒度毎の重みを設定し、これを元にしてプロセッサ間への探索候補の分割を最適化する。H-HPGM-FGDではデータの統計情報から支持度が高くなると予測される探索候補を見つけ出し、すべてのプロセッサに割り当てる。支持度の高い探索候補は処理負荷の高い要素であるため、これらを個々のプロセッサ毎に処理することにより、負荷の集中を回避することが可能となる。 提案した並列処理方式および負荷分散手法を当研究室で構築した100台のパーソナルコンピュータをATMネットワークで接続したPCクラスタ上に実装し、約1GBの大容量データベースを用いた性能評価を行い、各手法の有効性を調べた。図2に処理時間、CPU処理負荷の分布、台数効果を示す。最小支持度が小さい場合、単純な並列化であるNPGMの処理性能が急激に低下する。結果から、H-HPGMのようにデータの分類階層構造を考慮することにより通信負荷を低減し、単純なハッシュ分割(HPGM)と比較して処理性能が向上する。しかし、H-HPGMでは探索候補の分割の粒度が粗いため、図2(c)に見られるようにプロセッサ間の負荷の偏りが大きくなる。H-HPGM(flat+all)ではデータの統計情報を用いることにより探索候補の支持度を予測し、探索候補の分割を最適化する。これにより、処理時間が低減し、負荷の偏りを軽減することができている。しかし、図2(d)に見られるようにプロセッサ数が増加すると十分な処理性能を得ることができない。一方H-HPGM-FGD(flat+all)は、処理時間、負荷の偏り、台数効果のすべての結果において最も優れた性能を実現している。H-HPGM-FGD(flat+all)は支持度が高くなると予想される探索候補を見つけ出し、それらを複製することにより処理負荷の均衡化を図る手法であり、これにより効果的に負荷の偏りを軽減し、良い台数効果を達成することを確認した。 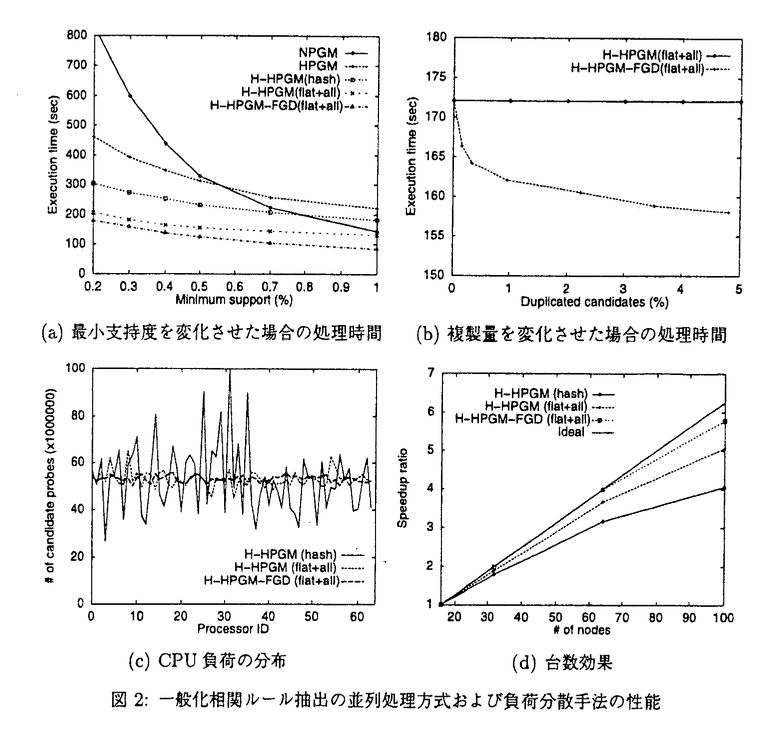 図2:一般化相関ルール抽出の並列処理方式および負荷分散手法の性能 図2:一般化相関ルール抽出の並列処理方式および負荷分散手法の性能 本論文は、大規模システム上における大容量データベースに対するデータマイニング処理の高速化にはデータベースの分割と探索候補の分割による並列処理方式が有効であること、および、探索候補の分割の最適化、一部の探索候補を複製して処理する手法により並列処理方式の処理性能を更に向上することが可能であることを示した。 |