コヒーレンスの取れた共有アドレス空間は並列計算にとって魅力的なプログラミング環境を提供する。ソフトウェアDSMは実行時に共有アドレスを提供し、多種多様なアプリケーションを扱うことが可能で、特殊な通信同期ハードウェアがない既存の分散システムに低コストで実装可能な方式である。ソフトウェアDSMの性能を向上させるには、コンパイラの最適化、キャッシュ管理プロトコルの最適化、ランタイムシステムの最適化、並びにそれらを可能にするインターフェイスが必要である。 最適化を可能にするインターフェイスとして、ADSMとUDSMが挙げられる。これらは共有メモリとメッセージパッシングを利点を統合したシステムである。キャッシュ管理にユーザレベルのコードを流用する。UDSMは完全にユーザレベルのセグメントベース機構で、ADSMはページ管理機構を流用するページベース機構である。UDSMは共有領域への読み出しと書き込みの両方に対してコンパイラ/プログラマに最適化の機会を提供する。一方、ADSMは共有領域への書き込みに対してコンパイラ/プログラマに最適化の機会を提供する。 コンパイラの最適化は、キャッシュ管理を行うユーザレベルのコードに対してなされる。つまり、キャッシュ管理に伴う通信と命令の最適化を実行する。上記方式を実現するものとして、我々は共有メモリプログラムに対する最適化コンパイラRemote Communication Optimizer(RCOP)を開発してしてきた。RCOPは共有メモリプログラムを直接解析して、緩和されたプロトコルの元で、RCOPは別名情報と区間解析に基づく冗長性削除のフレームワークを使って、プログラムの持つ階層的構造を最大限に利用する。我々は上記方式を実現するために、1)手続き間ポインタ解析と、2)冗長性削除のデータフロー方程式を区間解析の手法で解くことで、共有アクセス集合を手続き間で計算する手法を実装してきた。特に区間のサマリを求める際にループ変換で使用される最適化技法から流用されたCoalescing変換、fusion変換、冗長なインデクス変数の削除を使用する。 上記実装により、RCOPは共有アクセスを正確に検知し、冗長なキャッシュ管理コードを削減し、複数のキャッシュ管理コードを結合する最適化が可能になる。更に、共有書き込み時に、コヒーレンスを保たないようにするhome-onlyプロトコルをサポートできる。 プロトコルの最適化を実現するために、我々は緩和されたメモリモデルを実現する複数のキャッシュ管理プロトコルを実装してきた。AP1000+の従来のランタイムシステムに基づくプロトタイプ上の実験を通じて、キャッシュ管理プロトコルとしてデータが常に最新になるようなhomeを設けることが大事であり、同期のコストが比較的大きいということが明らかになった。 ランタイムシステムの最適化を可能にするために、以下の方式を提案してきた。まず、各キャッシュに対して正確な更新情報を維持することは高オーバヘッドにつながるので、最新のバリア同期から変更されたかどうかを1bitで判定するようにした。その結果、複雑な時間情報管理のオーバヘッドが削減され同期のコストが削減される。次に、書き込み時のキャッシュ管理ルーチンでプラットームが提供する大量データ転送を活用し、homeを直接更新する。これにより、homeは常に最新の状態になる。更に、細粒度の通信は実行時にパケットをコンバイニングすることで回避する。我々は上記システムをワークステーションクラスタ上の汎用オペレーティングシステムSSS-CORE上に実装してきた。SSS-COREが提供する仮想化され保護された高速ユーザレベル通信機構MBCFを利用して、大量データ転送と遠隔メモリの直接参照を実行する。 これまで提案してきた最適化技法をSPLASH-2ベンチマークを用いて、ADSM,UDSMの上で評価した。本実験で得られた知見は以下の通りである。 表1に示されているように、9個の実アプリケーションを実行させたところ、ADSMにおけるキャッシュ管理のオーバヘッドは、RCOPの最適化により本来の計算時間に対して、0.017%から8.9%に押さえられることが分かった。UDSMにおけるキャッシュ管理のオーバヘッドは、3.3%から21%に押さえられることが分かった。 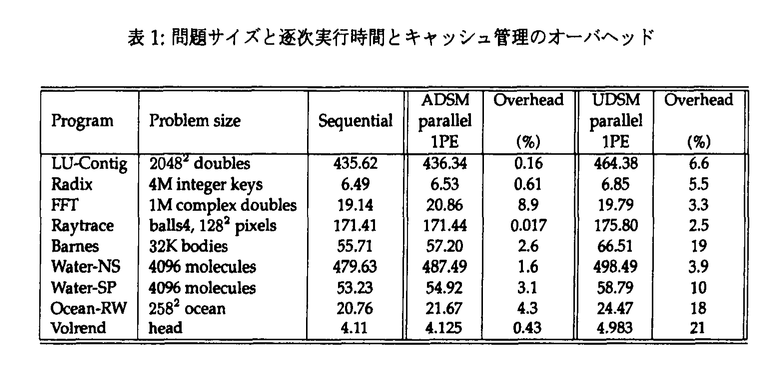 表1:問題サイズと逐次実行時間とキャッシュ管理のオーバヘッド 表1:問題サイズと逐次実行時間とキャッシュ管理のオーバヘッド 16台の実行における最適化の効果は図1に示されている。我々の提案する最適化が有効であることが分かる。 共有書き込みの最適化は通信の最適化につながり、共有読み出しの最適化は命令の最適化につながり、全てのアプリケーションに対して効果があることを確認した。特に規則的で粗粒度な参照パタンを持つアプリケーションに対して、高い高速化率を得た。 home-onlyプロトコルは粗粒度の読み出しパタンを有するが、書き込みは細粒度になってしまうようなアプリケーションに対して効果的であることを確認した。 この結果はソフトウェアDSMにおける最適化コンパイラの支援は重要であることを示している。また、この結果からADSMの性能を支配しているのは通信オーバヘッドであり、UDSMの性能を支配しているのはキャッシュ管理命令のオーバヘッドであることが確認できた。 図3はADSM、UDSMにおける逐次実行時間に対する高速化率を示したものである。両者の比較から、ADSMは細粒度アクセスを行うアプリケーションに対して不必要なデータ転送を行うことが性能のボトルネックになっていることが発見された。UDSMではADSMで問題になるfalse sharingと不必要なデータ転送は解決されるが、キャッシュ管理命令のオーバヘッドがボトルネックになることが発見された。 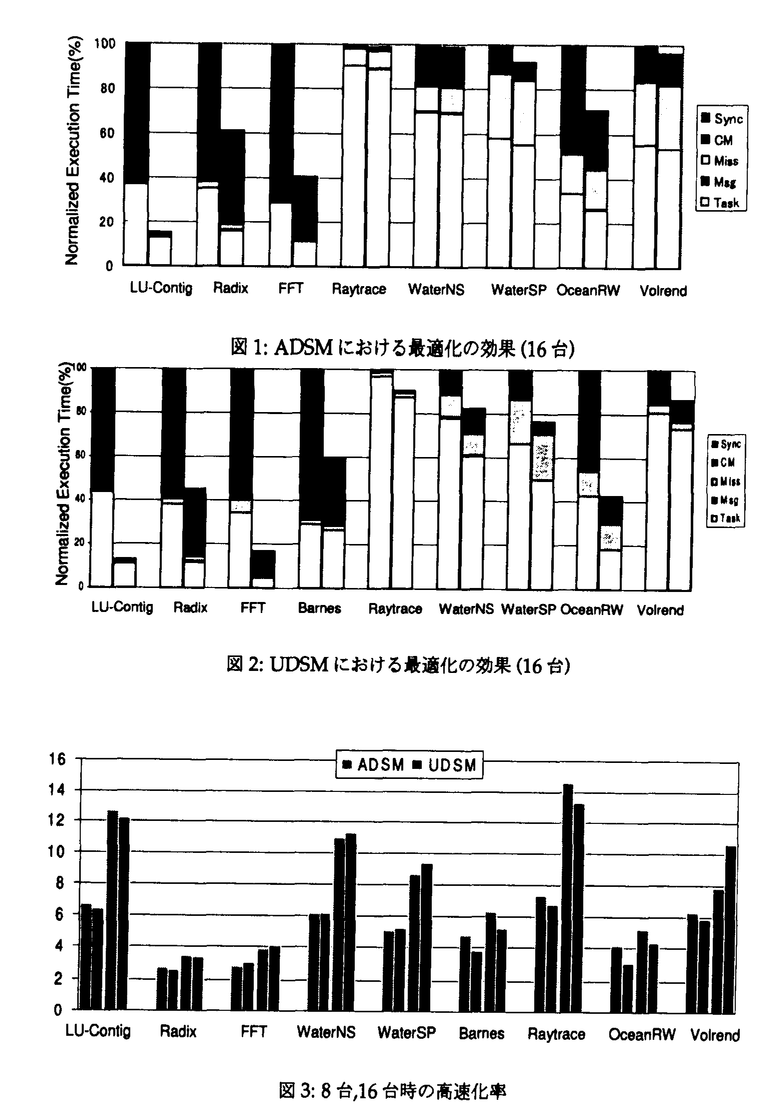 図表図1:ADSMにおける最適化の効果(16台) / 図2:UDSMにおける最適化の効果(16台) / 図3:8台,16台時の高速化率 図表図1:ADSMにおける最適化の効果(16台) / 図2:UDSMにおける最適化の効果(16台) / 図3:8台,16台時の高速化率 本評価を通じて、最適化のソフトウェアDSMにおける重要性を確認した。特に共有読み出し、共有書き込み共にユーザレベルで実現されるUDSMにとっては提案された最適化方式が有効であることを確認した。上記の結果はコンパイラの支援を受けた分散共有メモリシステムを汎用の分散システム上に構築することで、高性能並列計算資源が得られることを示唆している。 |