近年の計算機の高速化、パーソナル化に伴い、計算機がより身近なものとなってきた。しかしながら、だれもが気軽に利用できる計算機の利用環境を実現するためには、我々が日常コミュニケーション手段として用いている音声によるインタフェースが必要である。音声を利用して、人間と計算機が人間同士のように対話できれば、誰もが計算機のもつ大規模な情報や高速な計算能力を享受することが可能になる。 このような背景の基、音声や自然言語の認識理解の研究が進められている。しかし、これらの研究の多くは、書き言葉を対象としている。我々が日常用いている音声による対話は話し言葉による対話であり、書き言葉とは色々異なった特徴を有する。一般に、書き言葉は論理性が重視される言葉である。このため、文の文法的な整合性、論旨の一貫性などが求められる。しかし、一部の特殊なフォーマルな対話を除けば、話し言葉では柔軟性が要求される。すなわち、言い間違えば言い直せばよいし、前に言ったことがおかしければ訂正すればよい。また、話した内容に不足があれば、情報を追加する発話を行うと言う立場である。フォーマルな席で疲れるのは、この会話の柔軟性の利点が奪われるためである。また、話し言葉のもう一つの特徴として、発話が音響的にも文法的にも曖昧になることがあげられる。例えば、話し言葉では文が短くなる傾向があり、文脈や常識に基づく多くの省略がなされる。本研究の目的は、話し言葉により問い合わせ(あるいは応答)可能な情報システムにおけるマンマシンインタフェースの実現を目的としている。すなわち、機械と人間が人間同士のような対話により、検索などを行うことを可能にする対話処理の実現を目的としている。 このような対話を実現するためには、話し言葉の持つ会話性のよさを失わない柔軟な理解能力を実現する必要がある。話し言葉や書き言葉の理解は解釈問題の1つである。この解釈問題の特徴は、「最終的に得られる結果はただ1つ(実際には曖昧性のため絞りきれないことがある)に限られる」ことである。このため、入力の曖昧性により処理の途中段階(例えば、形態素解析、統語解析など)で生じる数々の解釈(仮説)をいかに効率よく枝刈りしていくかが大きな課題である。話し言葉では、先に述べたように書き言葉に比べで、音響的にも文法的にも曖昧性が増加するため、より効率のよい枝刈りが必要となる。このような話し言葉を、我々が正しく理解し、対話を進めていけるのは、発話者が文字に相当する情報(本論文では、この情報を以下音韻情報と呼ぶ)以外のイントネーションや表情、ジェスチャーといった色々な情報により伝えたい内容を効率よく正確に伝達しているためである。また、話の内容を理解する場合にも、文脈情報や常識などの多くの情報や知識を用いて効率よく理解している。このため、音韻情報以外のイントネーションやジェスチャー、さらに文脈、常識などの色々な情報や知識をも用いて相手の意図を理解していく必要がある。 従来、このような情報や知識の統合処理を目的として開発された代表的な方式として、Hearsay-IIの黒板モデルとHMM(Hidden Markov Model)がある。前者は、柔軟な知識の統合の枠組みを提供する。後者はマルコフモデルによる一貫した制約の取り扱いを可能にし、効率のよい処理を実現する。しかし、後述するようにどちらの方式も問題があるため、両者を上手く統合して利用する必要がある。HMMは基本的には最適化問題を解く。このため、認識対象の区間とその区間内の構造を規定する必要がある。このため、文節レベルのような文脈自由文法で記述できる範囲の認識への適用が望ましい。しかし、音声などは句読点などで区切られていないため、認識区間を切り出せない。さらに、言い間違いや言いよどみが生じる問題がある。このため、音韻情報のみからでは非常に多くの解釈が生じてしまう。一方、後者の黒板モデルは意味、文脈あるいは常識といった知識を統合する必要のある理解処理への適用が望ましい。しかし、黒板モデルは複数の知識を統合できる枠組みを与えているのみであり、効率のよい知識の利用法を組み入れないと非常に効率が悪い。例えば、話し言葉では文脈や常識に基づき多くの省略がなされる。そして、これが原因で、時には文法的、意味的に正しくない文となる場合がある。このため、この省略を文法や意味、文脈、常識などの各種の知識を用いて補足する必要がある。しかし、補足の対象となる文脈や常識等は非常に多く存在するため、効率のよい知識の適用が重要である。 本論文は、主に話し言葉の認識・理解における、このような音韻情報の周辺にある、韻律や文脈、常識などの情報の利用方法ならびに利用のための枠組みを提案するものである。 1章では、自然言語や音声の認識・理解システムの構成ならびに各章の位置づけについて述べる。システム構成を図1に示す。 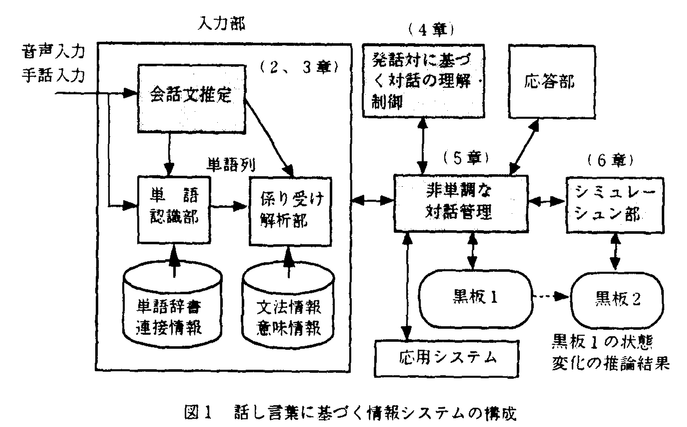 図1 話し言葉に基づく情報システムの構成 図1 話し言葉に基づく情報システムの構成 2章では、音声において文字に相当する音韻情報とともに、伝えたい内容を伝達する上で重要な情報であることが知られている、声の抑揚や強制などの韻律情報の利用法について述べる。韻律情報は、アクセントにより「雨」と「飴」の単語の違いを表現する以外に、文の意味に関係する文の構造を表現するほか、話者の感情や意志、意図などをも表すことが知られている。このうち、文の構造情報は、機械と人間の間の対話で最も重要な入力の認識・理解に直接関係する情報である。このため、ここでは韻律情報から文の構造を推定するための方法を提案する。従来、丁寧に発話された文を対象として、文を文節などに分割するための手段として韻律情報を利用する研究があった。ここでは、さらに自然な会話文の分割をも可能にするとともに、文の構造(係り受け構造)を抽出可能な方式を提案する。これにより、音韻情報からの単語の認識の曖昧性のみでなく、文の構造の曖昧性をも削減できる。 3章では、聴覚障害者のコミュニケーション言語である手話を対象として、音声の韻律情報に相当する特徴の抽出法ならびにその利用法について述べる。(1)手話は、日本語とは異なる独自の体系を持った言語である。しかし、研究段階の言語であるため、まだ記述言語が存在せず、体系化された文法などがない。このため、日本語等に比べて文法に関する情報を制約として十分に用いることができない。(2)手話は、格助詞が存在しないため、格に基づく意味制約を十分に用いることができない問題がある。このため、パターン認識レベルでの何らかの絞り込みが重要である。ここでは、とくに、手話の動作のリズムに基づく、入力文の単語単位へのセグメンテーション法を提案する。 4章では、省略や代名詞の補足における文脈情報利用のための対話管理法について述べる。省略や代名詞化は、過去の発話と関連してなされることが多い。対話の場合は、さらに自分の前の発話のみでなく、相手の発話との関連をも認識する必要がある。ここでは、対話を発話とその応答の対(発話対)により捕える管理法を採用した。この管理法は発話間の関連を捕える有効な方式であるが、実際の対話では発話対を構成しない発話が存在するなどの問題がある。ここでは、発話対が新たな質問を生成するという新しい考え方を導入することにより、この問題を解決する。また、互いに独立して動作する4つの対話処理部で対話を処理する構成をとることにより、単純な制御による対話管埋を実現する。 5章では、解釈を間違った場合にも対話を停止することなく、間違いを修正して対話を続けることが可能な対話管理法の枠組みについて述べる。対話はリズムが重要であり、このためある程度の解釈の曖昧さは、相手に問い合わせることなく、いずれかの解釈が正しいとの仮定のもとに話を先に進める。また、話者は一定の規則に従って省略を行なうが、まれにその規則に従わない場合もある。このような場合、システムは間違った解釈をしてしまう。そして、話が進むにつれて利用者との間で話に矛盾が生じてしまい、それ以上対話を進められなくなる。ここでは、この矛盾の原因をシステムが自動的に検出、解消し、対話を進めることが可能な対話管理を実現するため、仮定に基づいた真理保全機構(ATMS;Assumption based Truth Maintenans System)を導入する。しかし、ATMSを単に導入するのみでは、時間の進行により状態の変化するデータを管理できないなど解決すべき問題がある。ここでは、利用者の発話が入力される度に形成される世界(対話の世界と呼ぶ)を想定することにより、上記問題を解決し非単調な対話の制御を可能とする。 6章では、常識や対話により話される世界を表現するための定性推論の推論能力の向上法について述べる。常識において、上位下位概念や全体部分関係などの静的な関係は意味ネットワークなどにより表現可能である。しかし、会話では、さらに動的な常識に基づいて省略がなされることも多い。例えば、「水を火にかけ、その沸騰した湯に〜」の文を理解するためには、後の文の「湯」が前文の「水」と同じものであることを認識する必要がある。このためには、火にかけた水は沸騰した湯になる常識、すなわちシミュレーション能力をシステムに組み込む必要がある。定性推論は、このような正確なモデル化がしにくい常識による推論を定性的に実現しようとする方式である。ここでは、モデルのパラメータが予め指定できない場合やさらに系が不連続な挙動を含む場合のシミュレーションをも可能とする方式について述べる。 7章で、以上の研究の結論を述べる。 |