| 内容要旨 | | 本論文は確率的知識を対象とした機械学習の問題を,計算論的学習理論の立場から扱ったものである.機械学習とは,機械(計算機)が学習することであり,計算論的学習理論(以下,学習理論と記す)とは機械学習を計算論の立場から研究する分野である.すなわち,学習という行為を計算として捉え,その難しさを解析し,効率的な学習アルゴリズムの設計に役立てるものである.本論文では第2章以下で,上記テーマについて四つの話題を取り上げる. 第2章では,確率的知識の学習の基礎を成す,パラメータ推定量の構成について考察する.推定量を構成するとき,いくつかの方法がある,この中で,Bayes推定量,MDL(Minimum Description Length)推定量,バイアス補正した最尤推定量をとりあげ,主に指数型分布族に用いた場合の相互の関係を考察する. 確率分布のクラスS={p(x| )|∈ )|∈ }(x∈X)を考え, }(x∈X)を考え, ()をの上の事前分布とする.標本xN=x1…xNに関するBayes推定値は∫p(x|)(|xN)dである((|xN)は事後分布).Bayes推定量をi.i.d.情報源のユニバーサルデータ圧縮に用いた場合,Jeffreys事前分布(det|gij|)1/2d(gはFisher情報行列)を採用したときに冗長度についてミニマックス性を持つことが知られている.例えばSがBernoulli情報源のクラスの場合(X={0,1},p(x|t)=tx(1-t)1-x),Laplace推定量(k+0.5)/(N+1)(ただし ()をの上の事前分布とする.標本xN=x1…xNに関するBayes推定値は∫p(x|)(|xN)dである((|xN)は事後分布).Bayes推定量をi.i.d.情報源のユニバーサルデータ圧縮に用いた場合,Jeffreys事前分布(det|gij|)1/2d(gはFisher情報行列)を採用したときに冗長度についてミニマックス性を持つことが知られている.例えばSがBernoulli情報源のクラスの場合(X={0,1},p(x|t)=tx(1-t)1-x),Laplace推定量(k+0.5)/(N+1)(ただし )がミニマックス推定量である.ユニバーサルデータ圧縮は学習理論における逐次型学習問題と強い関連があり,上記のミニマックス性は,学習問題においても重要な意味を持つ.Bayes推定値は一般にSに属さないが,これをSに射影(-1-射影)して得られる推定量を射影Bayes推定量と呼ぶ.また,事前分布に関するMDL推定値は )がミニマックス推定量である.ユニバーサルデータ圧縮は学習理論における逐次型学習問題と強い関連があり,上記のミニマックス性は,学習問題においても重要な意味を持つ.Bayes推定値は一般にSに属さないが,これをSに射影(-1-射影)して得られる推定量を射影Bayes推定量と呼ぶ.また,事前分布に関するMDL推定値は (-ln p(xN|)+1/2・ln det|gij()|-ln ())である.ここで,Bernoulli情報源の場合に,tについて一様な事前分布を用いると,やはりLaplace推定量になる. (-ln p(xN|)+1/2・ln det|gij()|-ln ())である.ここで,Bernoulli情報源の場合に,tについて一様な事前分布を用いると,やはりLaplace推定量になる. 指数型分布族には -座標と -座標と -座標という座標を取れるが,情報幾何の観点からは,これらは互いに双対な関係にある.指数型分布族について以下を示した. -座標という座標を取れるが,情報幾何の観点からは,これらは互いに双対な関係にある.指数型分布族について以下を示した. ・Jeffreys事前分布を用いた射影Bayes推定量と,-座標について一様な事前分布(d)を用いたMDL推定量のいずれもが,-座標についてバイアス補正した最尤推定量とオーダ1/Nの項まで一致する. ・-座標について一様な事前分布(d)を用いた射影Bayes推定量と,Jeffreys事前分布を用いたMDL推定量のいずれもが,最尤推定量(について不偏である)とオーダl/Nの項まで一致する. この結果は,冗長度に関するミニマックス性とに関する不偏性との間に何らかの関係があることを示唆している.また,Jeffreys事前分布はdとdの相乗平均に一致することに注意すると,両者の間に一種の双対性があることを示唆していると考えられる.さらに,MDL推定量やバイアス補正した最尤推定量を用いて,一般に求めることが困難なBayes推定量を効率的に近似出来る可能性を与えている. また,以上の結果を有限アルファベットに関するMarkovモデル,および曲指数型分布族の場合に拡張した.特にMarkovモデルに関して,Jeffreys事前分布を用いたBayes推定量の近似式を求めた.Markovモデルについては,この推定量を求めることが実際に困難であることが指摘されていた. 第3章と第4章は,確率的PAC(Probably Approximately Correct)学習モデルに関わるものである.PAC学習モデルは学習理論における最も基本的な学習モデルの一つであり,確率的PAC学習モデルとは,特に確率的知識表現を対象にしたものである.このモデルでは,知識表現のクラスCを学習するときに,精度 を1- を1- 以上の確率で達成((,)-学習)するための標本の数と計算量を問題にする.精度は,Kullback-Leibler情報量(KL情報量),Hellinger距離,二乗誤差等の基準で測られる.(,)-学習するために十分な標本数を1/,1/,および学習のターゲットの複雑さ(またはCの複雑さ)で表したものを必要最小事例数(sample complexity)の上界という.クラスCを,多項式の必要最小事例数と,多項式の計算時間で学習するアルゴリズムをCのPAC学習アルゴリズムという.特に,Cがパラメータ数の異なる高々可算個のパラメトリックモデルから成る場合は,統計学におけるモデル選択問題を含んだ学習問題になる. 以上の確率で達成((,)-学習)するための標本の数と計算量を問題にする.精度は,Kullback-Leibler情報量(KL情報量),Hellinger距離,二乗誤差等の基準で測られる.(,)-学習するために十分な標本数を1/,1/,および学習のターゲットの複雑さ(またはCの複雑さ)で表したものを必要最小事例数(sample complexity)の上界という.クラスCを,多項式の必要最小事例数と,多項式の計算時間で学習するアルゴリズムをCのPAC学習アルゴリズムという.特に,Cがパラメータ数の異なる高々可算個のパラメトリックモデルから成る場合は,統計学におけるモデル選択問題を含んだ学習問題になる. 第3章では,KL情報量を精度の基準に用いたときのモデル選択を含んだ確率的PAC学習問題の必要最小事例数について考察する.Hellinger距離を精度の基準に用いた場合は,Yamanishiによる結果が知られている.それは,有限分割型確率的規則(条件付き確率分布)というクラス(FPと書く)の学習問題に関するものである.それによると,(モデル選択に関する)MDL推定量を用いると,必要最小事例数がf=1/・(|M*|ln(|M*|/)+l(M*)+ln(1/))のオーダで上界される.ただし,l(M*)は真のバラメトリックモデルM*の記述長,|M*|はM*のパラメータ数を表す.しかし,KL情報量についてのこのような結果は従来得られていない.本論文ではまず,2maxx∈X(ln(2/p2(x)))・D(0)(p1‖p2)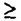 D(-1)(p1‖p2)という不等式を示した.ただし,p1,p2は有限集合X上の確率分布であり,D(-1)はKL情報量,D(0)はHellinger距離を表す.この不等式を利用するとYamanishiの結果をKL情報量に関するものに変換出来て,O(f ln f)なる必要最小事例数の上界が得られる.ただし,パラメータ推定量にLaplace推定量に類するものを採用するという変更を加える.また,Helliger距離に関するYamanishiの結果の若干の一般化も行い,FP以外のいくつかのクラスについて同様の結果を得た. D(-1)(p1‖p2)という不等式を示した.ただし,p1,p2は有限集合X上の確率分布であり,D(-1)はKL情報量,D(0)はHellinger距離を表す.この不等式を利用するとYamanishiの結果をKL情報量に関するものに変換出来て,O(f ln f)なる必要最小事例数の上界が得られる.ただし,パラメータ推定量にLaplace推定量に類するものを採用するという変更を加える.また,Helliger距離に関するYamanishiの結果の若干の一般化も行い,FP以外のいくつかのクラスについて同様の結果を得た. 第4章では,確率的PAC学習モデルの計算量の側面を考察した.確率的規則の凸線形和のクラス(混合型分布族)をKL情報量に関してPAC学習するアルゴリズムを提示する.ここでも,KL情報量について収束を保証するために,Laplace推定量に類する推定法を用いる.このクラスの場合,その元は連続パラメータのみで指定されるため,学習問題は線形制約付きの最適化問題に帰着する.ここでは,この最適化問題を解くために,Rosenの勾配射影法というアルゴリズムを少し変形して用いる. 第5章では,新しい逐次型(on-line)学習モデルを提案する.これは,学習の基準に学習者の利益という概念を導入したモデルである.しかも,学習に利用出来る情報は利益が得られたかどうかであるとする.このモデルでは,学習することと利益をあげることが分離出来ず,トレードオフを生じる.このような特徴をもった新しい学習モデルを提案し,最適選択の逐次型学習モデルと名付ける.これは学習モデルに,より現実的な面を採り入れる一つの方法である.ここでは,このモデルの中でさらに限定した問題であるロブパス問題という問題を定義し,解析した. ロブパス問題とは次の様なゲームに例えられる.このゲームはプレイヤーAが機械g∈Gを相手にテニスをする(gが学習対象)もので,Aは各時点iにおいて, i∈{L,P}を選択しgに渡す(LとPはそれぞれロブとパスを表す).gはiが入力されると,i∈{0,1}を返す(1はAがポイントをあげたことを表す).ただし.確率 i∈{L,P}を選択しgに渡す(LとPはそれぞれロブとパスを表す).gはiが入力されると,i∈{0,1}を返す(1はAがポイントをあげたことを表す).ただし.確率 (ri)(riは時点i-1までにAが選んだLの相対頻度)で1を,確率1-(ri)で0を返すものとする.ここで, (ri)(riは時点i-1までにAが選んだLの相対頻度)で1を,確率1-(ri)で0を返すものとする.ここで, (r)はの成功率を表し,fLは傾きが負の,fPは傾きが正の一次関数で,∃r∈[0,1]fL(r)=fP(r)を満たすものとする.Aの目標は (r)はの成功率を表し,fLは傾きが負の,fPは傾きが正の一次関数で,∃r∈[0,1]fL(r)=fP(r)を満たすものとする.Aの目標は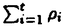 をなるべく大きくすることである.ここで,gをゲームとも呼ぶ.gはfLとfPで指定出来るので,g=(fL,fP)とする.この問題の特徴は,Aが自身の行動を通じてgに関して学習することと,学習に利用出来る情報が,選択した行動の結果である利益そのものである点である.学習の評価にはリグレットという概念を用いる.Aのgに対する期待累積リグレットR(A,g,t)は,Aによるt回目の試行までの勝ち数の期待値から,gに特化した理想的なプレイヤーによるt回目の試行までの勝ち数の期待値を引いたものである.また,R(A,G,t)= をなるべく大きくすることである.ここで,gをゲームとも呼ぶ.gはfLとfPで指定出来るので,g=(fL,fP)とする.この問題の特徴は,Aが自身の行動を通じてgに関して学習することと,学習に利用出来る情報が,選択した行動の結果である利益そのものである点である.学習の評価にはリグレットという概念を用いる.Aのgに対する期待累積リグレットR(A,g,t)は,Aによるt回目の試行までの勝ち数の期待値から,gに特化した理想的なプレイヤーによるt回目の試行までの勝ち数の期待値を引いたものである.また,R(A,G,t)= R(A,g,t)をAのGに対する期待累積リグレットといい,R(G,t)=infAR(A,t)をGの期待累積リグレットという(これらのリグレットの定義は直感的なもので,厳密には正しくない.).このモデルにおいて,三つのアルゴリズムを提案し,リグレットを評価した.ただし,ここでfL(0)=fP(1)という制約(マッチングショルダー条件)をおいた.これを満たすgのクラスをGMSと書く.GMSについては,R(GMS,t)=O(t5/7)という結果を得た.また,GMSの様々な部分クラスに関して,それぞれに応じたオーダのリグレットの上界を得ている.特に,非常に限定したクラスGについては,R(G,t)=O(ln t)となることを示した.これは,ここで示した下界R(GMS,t)= R(A,g,t)をAのGに対する期待累積リグレットといい,R(G,t)=infAR(A,t)をGの期待累積リグレットという(これらのリグレットの定義は直感的なもので,厳密には正しくない.).このモデルにおいて,三つのアルゴリズムを提案し,リグレットを評価した.ただし,ここでfL(0)=fP(1)という制約(マッチングショルダー条件)をおいた.これを満たすgのクラスをGMSと書く.GMSについては,R(GMS,t)=O(t5/7)という結果を得た.また,GMSの様々な部分クラスに関して,それぞれに応じたオーダのリグレットの上界を得ている.特に,非常に限定したクラスGについては,R(G,t)=O(ln t)となることを示した.これは,ここで示した下界R(GMS,t)= (ln t)と一致する. (ln t)と一致する. |