| 内容要旨 | | シリコンチップの上に複雑で高性能の論理回路を実現するためには、物理的により小さな論理回路を作らなければならない。このような微小な論理回路はデジタル回路でありながら、アナログ的な電磁効果の影響を大きく受けるため、大規模論理回路の設計においては電気電子レベルの効果の制御が必要である。このため回路の電磁効果を解析する回路シミュレーションは、回路設計において不可欠な要素であり、大規模回路シミュレーションの速度性能は回路設計の効率と精度に大きな影響を与える。回路シミュレーションの速度は、主に非線形回路要素の状態評価計算と連立一次方程式の求解の速さで決まるが、連立一次方程式の求解に要する時間は回路規模に対し線形以上に増加するため、大規模回路シミュレーションでは高速化の必要性がより高い。また、高速数値計算の手法として並列処理が注目を集めているが、連立一次方程式の求解に広く用いられてきた直接法は逐次性が高いため、効率的な並列化の障害の一つとなっている。このように、連立一次方程式の解法は大規模並列回路シミュレーションにおける最も重要な課題の一つである。 一般に回路シミュレーションに用いられる直接法には上記のような問題があるため、反復法を用いて回路シミュレーションを行なう研究もなされている。そのなかで特に注目を集めているものは波形緩和法であるが、この方法は適用範囲が極めて狭いという重大な欠点があるため、改良の研究は進んでいるものの、実用化はされていない。共役勾配法系の方法は速度性能が不十分で、研究は進んでいない。また最近、不完全LU分解に基づいた方法も提案されているが、研究の途上である。 本論文では大規模並列回路シミュレーションのための反復解法として、前処理つき緩和法と強制疎化LU分解法を提案する。前処理つき緩和法はリチャードソン法・ヤコビ法・ガウスザイデル法といった古典的緩和法に前処理を施すことにより収束性能を高めたものである。本論文ではこの前処理つき緩和法を超電導論理回路であるQFP回路に適用し、評価を行なう。QFP回路においてはジョセフソン素子のみが非線形回路要素であるため、連立一次方程式の係数行列の範囲がコンパクト集合となる。その集合の重心を代表行列として前処理行列に利用することにより、すべての回路状態に対して適用できる最適な前処理行列を事前に計算することが可能である。また、前処理行列の値の小さい要素を間引くことにより計算量を軽減させる行列の強制疎化、ベクトルの値の小さい要素を無視して前処理計算を行なうベクトル強制疎化、残差計算を省略するための緩和法の収束予測などの技術を提案した。この前処理つき緩和法を用いた回路シミュレータをワークステーション上に実装し、桁上げ先見回路つき加算器のシミュレーションを行ない評価した。その結果、大規模回路においては従来用いられてきた直接法を上回る速度性能が達成された。 ヤコビ法やリチャードソン法は自然で高い並列性を持っているが、その速度性能と並列性は前処理行列によって決定的な影響を受ける。高性能な並列前処理つき緩和法を実現するためには、(1)高い収束性能のために代表行列の逆行列に十分近く、(2)高い並列性のために陽的であり、(3)高い速度性能のために高い疎行列性をもつ前処理行列が必要である。そこで本研究ではこのような条件を満たす前処理行列として、強制疎化された陽的分解逆行列を提案した。一般に疎行列の陽的な逆行列は密であるが、LU分解によって得られた2つの三角行列の逆行列はいずれも疎である。この三角行列の逆行列のペアを陽的分解逆行列と呼ぶことにする。この行列ペアから、値が極めて小さく、取り除いても影響のない要素を取り除く(強制疎化する)ことにより、疎行列性を高めた行列が強制疎化された陽的分解逆行列である。これを前処理行列として用いることにより、前処理つき緩和法が本来持っている自然で高い並列性を十分に活かすことができる。本研究ではさらに、陽的分解逆行列の非零要素の数を抑えるアルゴリズムを提案した。このアルゴリズムは陽的分解逆行列を元の行列から直接求めるアルゴリズムにおいて、各段階で発生する新たな非零要索(フィルアウト要素)をgreedyに最小化することにより、普通用いられているMarkowitz-Tewarsonのフィルイン最小化アルゴリズムにくらべて10%程度非零要素数を削減することができた。また、前処理行列の生成を多段クラスタリングによって並列計算機上に実装し、高い並列化効率を達成した。 並列前処理つき緩和法の並列化効率は前処理部分の実装によって決定される。そこで本研究ではさらに強制疎化された陽的分解逆行列とベクトルとの積を効率的に並列実装する技術について研究を行なった。前処理行列は疎行列であるが、下三角行列の最後のいくつかの行と上三角行列の最後のいくつかの列はほぼ密になるという特徴がある。これらの密な行と列のために、通常の疎行列では見られることのないロードのインバランスや大域的な通信が必要となる。余計な通信を抑えるためには、行列のプロセッサへの割り付けはベクトルの割り付けにしたがって行毎、あるいは列毎に割り付けなければならない。分解逆行列は2つの行列のペアからなるが、それぞれの行列に別の割り付け方を使うことができるので、行行、行列、列行、列列の4通りの割り付け方が考えられる。ロードバランスについて比較すると、密な行や列が一つのプロセッサに集中しない列行割付が最適である。また、通信は列割付の場合は演算の後に、行割付の場合は演算の前に必要であるが、列行割付では2つの通信が1つにまとまるため、通信量が削減されることがわかった。さらに列行割付ではバタフライサムの技術を用いて効果的に通信量を削減することが可能である。このため、ロードバランスと通信量の両方の視点から、列行割付が最適であることが明らかとなった。また、バタフライ型と一対一型の通信方式を比較し、列行割り付けにおいては常にバタフライ型が優れていることを実装評価によって立証した。さらに、通信順序について、遠くの方から順に行なうfar-firstと近くから行なうnear-firstを実装比較した。Far-firstの方が通信の衝突が少なくなり性能が高いと期待されたが、実験では差はわずかであり、near-firstの方が速い場合もありうるという結果であった。これらの結果をもとに、前処理つきリチャードソン法を用いた並列回路シミュレータspartaを富士通社製並列計算機AP1000上に実装し、その性能を評価した。回路シミュレータの並列化効果は、プロセッサあたりのノード数と非線形要素数に依存し、これらが小さいほど並列化効率は下がる。QFP回路は半導体回路と異なり、非線形要素数がノード数に比べてかなり少ないため、プロセッサあたりの非線形要素数を合わせて並列化効率を評価すると、効率を過小評価することになる。しかしこの評価方法でも、他の研究と同様の並列化効率を達成することができた。逆にプロセッサあたりのノード数を合わせて並列化効率を評価すると過大評価となるが、この場合には他の研究をはるかにしのぐ高い並列化効率を示した。これにより、前処理つき緩和法による回路シミュレーションの高い並列化効率が実証された。 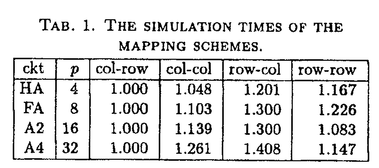 TAB.1.THE SIMULATION TIMES OF THE MAPPING SCHEMES. TAB.1.THE SIMULATION TIMES OF THE MAPPING SCHEMES. 実用的な意味で高い並列化効率を達成するためには、回路シミュレーションの本体だけではなく、データや演算のプロセッサへの分配(仕事割り付け)も効率的に並列処理がなされなければならない。本研究では割付の性能が高く、効率的な並列実装の容易なアルゴリズムとしてモンテカルロ二分法を提案した。このアルゴリズムではデータをグラフとして表現し、これを辺で二分割することを繰り返して必要な数のクラスタに分割する。各二分割においては、まずグラフの任意の2ノードを選び、これらのノードからの距離の差によって各ノードにラベルを付ける。このラベルに従ってノードを2つのグループに分ける。分け方が複数ある場合には最適な分割を選ぶ。この処理を始点の2ノードの選び方を変えて繰り返し、最適な分割を最終的に選択する。実際には更に線形時間最適化を用いて分割の最適化を行なう。このアルゴリズムはグラフの大きさをN、反復回数をKとするとO(NK)の計算量を必要とする。反復回数Kと評価関数の結果の関係を調べた結果、実験した問題ではK=Nで十分であったが、小規模な問題ではさらにKを少なく取ることができた。このことから逆に大規模な問題では更に反復回数を増やさなければ最適な分割まで達しない可能性がある。また、他のいくつかのアルゴリズムと比較した結果、O(N)の計算時間のアルゴリズムに比べて割り付け性能が高いことが示された。また、モンテカルロ二分法は始点のノードをランダムにサンプルしているのでサンプリングを分散させることにより自明な並列処理が可能である。2段目以降の二分割は依存性があるが、依存性を緩めることによりおよそ2/3の並列化効率で並列実行はできる。このことは実装によって実証された。また、モンテカルロ二分割法の高い性能はspartaの高い並列化効率によっても実証されている。 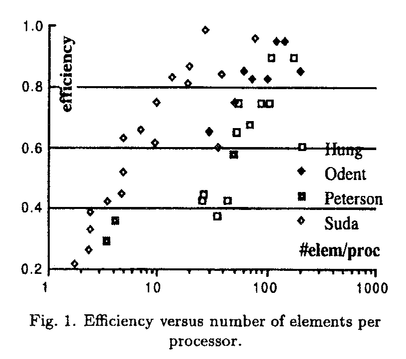 Fig.1.Efficiency versus number of elements per processor. Fig.1.Efficiency versus number of elements per processor.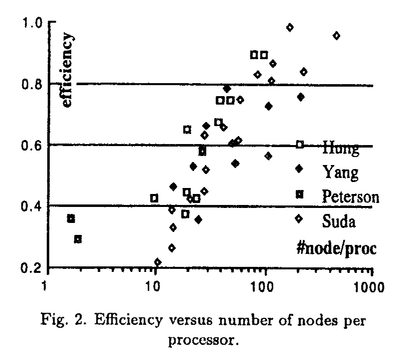 Fig.2.Efficiency versus number of nodes per processor. Fig.2.Efficiency versus number of nodes per processor. 以上のように前処理つき緩和法は大規模並列回路シミュレーションにおいて有効な方法であることが明らかとなったが、係数行列の範囲が理論的には有界でない半導体回路に対してこのアルゴリズムを適用することは、適当な前処理行列を見つけることが困難であるため容易でない。任意の回路に適用できるためには、回路シミュレーションを行ないながら動的に前処理行列を計算する必要があると考えられる。そこで本論文では、前処理行列の計算が最も簡単に済む強制疎化されたLU分解を前処理としたリチャードソン法をベースにして、前処理行列をLU分解の修正の技法を用いて更新する、強制疎化LU分解法を提案する。この方法は不完全LU分解緩和法において、不完全LU分解を修正する拡張を行なったものと考えることもできる。また、LU分解の修正において行列変化の小さい部分を無視することが行列変化の強制疎化と解釈することもできるので、LU分解において極限的に強制疎化を適用した方法と理解することも可能である。この強制疎化LU分解法は、行列変化の強制疎化を最大限にして修正を行なわないとすでに述べた前処理つき緩和法に一致し、逆に強制疎化を全く行なわないとLU分解法に一致する。このため、強制疎化の程度を調節して計算量と反復回数のトレードオフを解決することにより、最適な解法を構成することが可能である。そして不完全LU分解緩和法とLU分解部分修正緩和法とを包含する一般化された解法である。 本論文ではまず強制疎化LU分解法のアルゴリズムを定義する。強制疎化LU分解ではLU分解の強制疎化(不完全LU分解)、行列変化の強制疎化、代入計算におけるベクトルの強制疎化、残差行列の強制疎化、残差計算におけるベクトルの強制疎化の5つの強制疎化が適用され得る。残差計算における2つの強制疎化は単純な行列ベクトル積において値の小さいものを無視するものである。代入計算におけるベクトルの強制疎化では、三角行列の列とベクトル要素との積の計算を、ベクトル要素の値が小さい時に省略するものである。しかしこれはもともと代入計算の計算量は小さく、ベクトル要素の強制疎化の判定のオーバーヘッドのために有効でないことがわかった。行列変化の強制疎化のためには、不完全LU分解の修正アルゴリズムが必要である。これはLDU分解を利用することにより構成でき、更新型と再計算型とが可能であることがわかった。行列変化の疎行列性が高い場合には更新型が、行列変化が密に近い場合は再計算型が有利であると期待されるが、本研究では更新型を用いた。このようにLU分解の修正を用いることによって計算量を削減することができる一方で、いくつかの問題も生じる。枢軸順序や時間刻みを変更できないだけでなく、修正されない要素は不完全LU分解から強制疎化されない。このため強制疎化の閾値が変化する場合、不完全LU分解の疎行列性は最小閾値の値に強く依存することになる。  TAB.2.ITERATIVE ELU METHOD IN HIGH PRECISION TAB.2.ITERATIVE ELU METHOD IN HIGH PRECISION 強制疎化LU分解の疎行列性や収束性は強制疎化の閾値の設定によって決まる。閾値を十分小さくすればLU分解に近づき1反復で収束するので、閾値はこの値以上でなければ意味がない。この値はニュートン法の収束の様子から推定することができる。また、閾値の最小値が不完全LU分解の疎行列性を決めるので、閾値が極端に小さくならないように下限を設定することが望ましい。そこで閾値を1反復で収束する値と設定した下限との大きい方に設定することとした。この下限を設定値を変えて実験したところ、ほぼニュートン法の精度の半分が最適であることがわかった。これよりも設定値を大きくとると反復回数が増大するため遅くなり、逆に小さくとると疎行列性が急激に悪くなって性能が低下するのである。この条件では平均の反復回数が1.01回程度であるため、反復を全く行なわなくてもニュートン法の反復回数が1%程度増大するだけでシミュレーションが実行できる。このように反復を行なわないことにより残差計算のためのデータと計算が省略できるため、反復を行なう強制疎化LU分解法の1反復分よりも計算量が少なく済み、1%のニュートン法の反復回数の増大を十分補うことができる。この方法をlazy ELU法と呼ぶことにする。 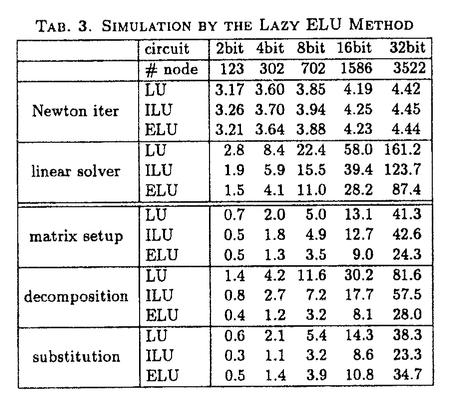 TAB.3.SIMULATION BY THE LAZY ELU METHOD TAB.3.SIMULATION BY THE LAZY ELU METHOD このlazy ELU法をワークステーション上に実装してECLを用いた桁上げ先見回路つき加算器のシミュレーションを行ない、不完全LU分解法・直接法と比較を行なった。その結果、lazy ELU法は直接法のほぼ半分の時間で連立一次方程式を解くことができた。これらの解決はそれぞれ行列の生成、分解、代入の3つのフェーズに分けることができるが、lazy ELU法ではLU分解の修正の部分は直接法のLU分解のおよそ1/3の時間で済むことがわかった。行列の生成でも修正されない要素が関係なくなる分速くなり、また代入計算でも疎行列性が向上しているので直接法よりも高速であった。不完全LU分解緩和法は疎行列性が高く代入計算が高速であるが、LU分解にlazy ELU法のおよそ倍の時間がかかるためlazy ELU法にはおよばなかった。強制疎化LU分解はLU分解に比べ計算の依存性が少ないためcritical path長が短くなり、並列処理に向いていると考えられる。しかし強制疎化LU分解の効率的な並列実装は、依存性が動的に決まるため容易ではなく、今後の課題である。 |
| 審査要旨 | | 本論文は6つの章から構成される.第1章では,この研究の重要性と目的について述べ,第2章では関連研究をサーベイしている.第3章では,前処理つき緩和法を導入し,高効率を達成するための方法について論じている.第4章は,前処理つきリチャードソン法の並列実行のための種々のアルゴリズムが開発・解析され,実際に並列計算機AP1000上での実装・実験を行なって,有効性の検証が行なわれている.第5章では,強制疎化LU分解法を提案し,その有効性を示すとともに,並列化について解析されている.第6章は,全体をまとめて本論文で得られた成果について述べている. シリコンチップの上に複雑で高性能の論理回路を実現するためには,物理的により小さな論理回路を作らねばならず,そのような微小な論理回路はデジタル回路でありながら,アナログ的な電磁効果の影響を大きく受けるため,大規模論理回路の設計においては電気電子レベルの効果の制御が必要である.このため,回路の電磁効果を解析する回路シミュレーションは,回路設計において不可欠な要素であり,大規模回路シミュレーションの速度性能は回路設計の効率と精度に大きな影響を与える.この大規模回路シミュレーションにおいて近年で最も重要な問題が,そこで現れる回路方程式に関する連立一次方程式の並列解法であり,本論文ではこの重要な問題に取り組んでいる. 本論文では,大規模並列回路シミュレーションのための反復解法として,前処理つき緩和法と強制疎化LU分解法を提案している.前処理つき緩和法はリチャードソン法・ヤコビ法・ガウスザイデル法といった古典的緩和法に前処理を施すことにより収束性能を高めたものである.本論文ではこの前処理つき緩和法を超電導論理回路であるQFP回路に適用し,評価を行なっている.QFP回路においてはジョセフソン素子のみが非線形回路要素であるため,連立一次方程式の係数行列の範囲がコンパクト集合となる.その集合の重心を代表行列として前処理行列に利用することにより,すべての回路状態に対して適用できる最適な前処理行列を事前に計算することが可能である.また,前処理行列の値の小さい要素を間引くことにより計算量を軽減させる行列の強制疎化,残差計算を省略するための緩和法の収束予測などの技術を提案している.さらにこの方法の並列処理について,陽的分解逆行列の非零数を抑えるアルゴリズムや負荷分散のための多段クラスタリング法などに関して詳細に検討している.また,通信量の最適化に関して行行,行列,列行,列列の4通りの通信方式を考察し,列行割付が最適であることを明らかにした. これらの結果をもとに,前処理つきリチャードソン法を用いた並列回路シミュレータspartaを並列計算機AP1000上に実装し,その性能を評価した.回路シミュレータの並列化効果は,プロセッサあたりのノード数と非線形要素数に依存し,これらが小さいほど並列化効率は下がる.QFP回路は半導体回路と異なり,非線形要素数がノード数に比べてかなり少ないため,プロセッサあたりの非線形要素数を合わせて並列化効率を評価すると,効率を過小評価することになる.しかしこの評価方法でも,他の研究と同様の並列化効率を達成することができた.逆にプロセッサあたりのノード数を合わせて並列化効率を評価すると過大評価となるが,この場合には他の研究をはるかにしのぐ高い並列化効率を示した.これにより,前処理つき緩和法による回路シミュレーションの高い並列化効率が実証された. 以上のように前処理つき緩和法は大規模並列回路シミュレーションにおいて有効な方法であることが明らかにされたが,係数行列の範囲が理論的には有界でない半導体回路に対してこのアルゴリズムを適用することは,適当な前処理行列を見つけることが困難であるため容易でない.任意の回路に適用できるためには,回路シミュレーションを行ないながら動的に前処理行列を計算する必要があると考えられる.そこで本論文では,前処理行列の計算が最も簡単に済む強制疎化されたLU分解を前処理としたリチャードソン法をベースにして,前処理行列をLU分解の修正の技法を用いて更新する,強制疎化LU分解法を提案している.この方法は不完全LU分解緩和法において,不完全LU分解を修正する拡張を行なったものと考えることもできる.また,LU分解の修正において行列変化の小さい部分を無視することが行列変化の強制疎化と解釈することもできるので,LU分解において極限的に強制疎化を適用した方法と理解することも可能である. 強制疎化LU分解の疎行列性や収束性は強制疎化の閾値の設定によって決まる.閾値を十分小さくすればLU分解に近づき1反復で収束するので,閾値はこの値以上でなければ意味がない.この値はニュートン法の収束の様子から推定することができる.また,閾値の最小値が不完全LU分解の疎行列性を決めるので,閾値が極端に小さくならないように下限を設定することが望ましい.そこで閾値を1反復で収束する値と設定した下限との大きい方に設定することとした.この下限を設定値を変えて実験したところ,ほぼニュートン法の精度の半分が最適であることがわかった.これらの考察をもとに,Lazy ELU法が提案されている.このlazy ELU法は直接法のほぼ半分の時間で連立一次方程式を解くことができる.また,強制疎化LU分解はLU分解に比べ計算の依存性が少ないためクリティカルパス長が短くなり,並列処理に向いていることが示されている. 以上を要約すると,本論文の提出者須田礼仁氏は,並列回路シミュレーションのための反復線形解法という情報科学における重要な問題について,詳細な検討をもとに新しい方法を提案し,それを並列プログラミングして有効性を検証した.数値計算アルゴリズムとしても,強制疎化を活用する新方法を与えた.これらの成果は並列回路シミュレーションと反復線形解法の研究に関する多大な貢献であり,本論文は今後の情報科学の発展に寄与する論文である.よって,須田礼仁氏は博士(学位)の授与される資格を有するものと認める. なお,本論文に述べられている研究成果は,小柳義夫氏との共同研究であるが,論文提出者が主体となって開発・解析及び検証を行なったもので,論文提出者の寄与が十分であると判断する. |