仮想計算機システム(VMS)の性能向上に関しては、それが実用化され、一般に広く使用されるに至るまでさまざまの角度から研究が行われてきた。そのなかで、本論文は、複数台の高性能仮想計算機(VM)をサポートし、各VMに、実計算機とほとんど同等の性能を与えるための性能設計に関するものである。本論文は、10章からなっている。第1章の概要に続き、第2章から第4章はソフトウェアによる性能向上方式を論述する。ハードウェアによる性能向上方式を第5章、第6章に述べる。第7章、第8章はVMスケジューリング方式に関係する。第9章に、本研究によって得られた方式のまとめと評価を論述する。最後に第10章に結果のまとめと将来の研究方向について述べる。 第1章では、本研究の背景と目的、内容の概要等について述べる。仮想計算機技術は、アーキテクチャを多重化する技術である。当初、VMはすべてソフトウェア(制御プログラム(ホストともいう))によるシミュレーションによってサポートされたために、実計算機の10倍以上のCPU時間がかかっていた。従来よりマイクロコード等による性能向上が図られ、業務運用のための一台の高性能VM(V=RVMと呼ばれ、システム全体で一台しか存在しない)と複数台のOS開発用VM(V=VVMと呼ばれ比較的低性能)方式が提案され実用に供されていた。これに対して、本研究においては、複数台のOSを同時に業務として運用することの必要性に応じ、複数台の高性能VM方式を提案し、その技術を確立することを目的とする。これによって、新旧OSによるオンライン運用や、複数OSの同時運用を行い可用性の向上を図ることができる。 第2章では、複数台定義可能な高性能常駐VM方式を提案した。常駐VM方式は、VMの主記憶領域をシステムの主メモリ上に連続的にマッピングするものである。このマッピング手段としてアドレス変換テーブルによる方法を提案した。後の第5章で、さらに効率的なハードウェアによる方式を提案する。VMオーバヘッドの主要因であるI/Oシミュレーションオーバヘッドを低減するため、I/O正常処理のFast Pathと常駐VMのアドレス属性を利用したCCW変換の高速化によるFast I/O-simulation方式を提案した。これにより、I/Oシミェレーションオーバヘッドを半減し、各常駐VMのCPU処理時間(VMのオーバヘッドを含む全CPU処理時間)は、高負荷に対して、従来、実計算機の約3倍のCPU時間がかかっていたものを、約2.5倍にまで削減することができた。 第3章では、オンラインシステムの移行用にVMSを用いるに当たり、その信頼性と操作性の向上方式について提案している。具体的には、複数VMの自動log-onや自動IPL、自動リスタート等である。これによって、オンラインシステムへの適用性を高めている。 第4章では、シャドウテーブル保守オーバヘッド削減方式を提案している。シャドウテーブルは、VM上のOS(ゲストOS)のアドレス変換テーブルとホストのそれを合成したアドレス変換テーブルである。ゲストOSの仮想アドレスをホスト実アドレス(ホストにとっての実アドレス)に変換する。このとき、ゲストOSのページング等によりシャドウテーブル保守のためのオーバヘッドが発生する。従来、そのページ無効化に対して該当ページアドレスが不明のため全シャドウテーブルを無効化していた。そこで、OSから情報を得ることによって該当のシャドウテーブルエントリだけを無効化する方式を提案した。これにより、VMのCPU処理時間は実計算機の約2倍にまで低減している。 第5章において、ハードウェアによる性能向上として、常駐VM用アドレス変換方式を提案した。これは、常駐VMの主記憶アドレスが持つ固定的対応関係(定数加算やOR演算等)と、ゲストOSのアドレス変換テーブルとの組合せ、連係をハードウェア的に直接サポートすることによりゲスト仮想アドレスをホスト実アドレスに変換する方式である。このアドレス変換方式を前提として、タイマ等の制御命令直接実行方式を提案した。これらによりシャドウテーブルを不要とし制御命令シミュレーションオーバヘッドを削減し、VMのCPU処理時間を実計算機の約1.5倍にまで削減した。従来研究において、唯一しか存在しないV=RVMに対して、その性能を実計算機とほとんど同等とするために、必要なI/Oリソースを専有化し、I/O命令、I/O割込みをハードウェアより直接実行する方式(I/O直接実行方式)が提案されていた。これに対して、本研究においてはじめて複数台の常駐VMに対してI/O直接実行方式を提案した。I/Oシミュレーションの一般的な場合は複雑であるためにソフトウェアによるシミュレーションが必要である。したがって、I/O直接実行のためには、パフォーマンス/コストを検討し、その適用範囲を制限して、ハードウェア技術を適用することが必要であることを示している。すなわち、本研究において、I/O直接実行のためには、常駐VMの適用、サブチャネル(I/O装置を表すオブジェクト)の専有化、ゲストCCWの直接実行、I/O割込み優先順位の専有化方式が基本技術であることを示した。以上によって各常駐VMのCPU処理時間は、実計算機の約1.1倍以下にまで削減され、実計算機とほぼ同等の性能を得ることができるようになった。 第6章では、I/Oレスポンスを高めるための動的チャネルパス再結合方式と上記I/O直接実行方式との両立性について論じた。従来、この両立性を得るために、各VMに排他的にチャネルパスを割り当てなければならなかった。しかし、これでは、VMSにおけるI/Oシステム構成の柔軟性に欠けるので、本研究では、VM間でチャネルパスを共有して、この両方式を同時使用可能とするVM用チャネルパスグループ管理方式を提案している。 第7章では、ホストマルチプロセッサにおけるTLB制御方式について提案する。従来、論理プロセッサのディスパッチの切替えにおいてそのconsistencyを保証するためにTLBを無効化していた。これに対して、そのような切替えにおいても有効なTLBエントリを再利用する方式を提案している。この方式により、平均命令実行時間がこれまでにくらべて約10%短縮される。 第8章では、ゲストマルチプロセッサ(マルチプロセッサモードで動作するVM)における過剰スピン制御方式を提案している。従来の実計算機モードでの制御方式だけでは不充分であるので、同一VM内の論理プロセッサを優先するいくつかの制御方式を提案し、それにより、過剰スピンの低減方式を明らかにしている。 第9章では、本研究によって得られた広範囲に適用可能なVMの性能設計と実現のための方式を論述する。さらに、本研究での各性能向上方式とその効果についてまとめた。 第10章に結果のまとめと将来のVM研究方向について述べる。 以上のように本論文は、ソフトウェア、ハードウェアの両面から複数台の高性能仮想計算機を実用化するための重要な方式を提案しており、この分野の技術の発展に多大の貢献をするものと評価することができる。なお、本論文の内容の一部は共同研究者による成果を含むが、いずれも論文提出者が主たる方式を提案し、中心となって研究を行ったものである。これによって、本審査委員会は、論文提出者梅野英典に博士(理学)の学位を授与することができると認める。 | 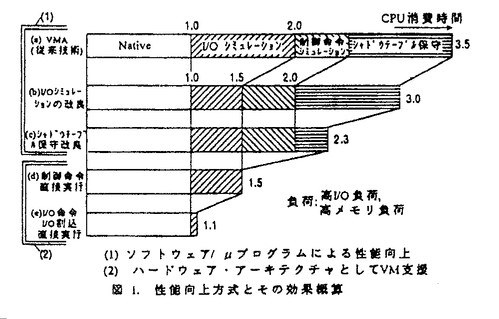
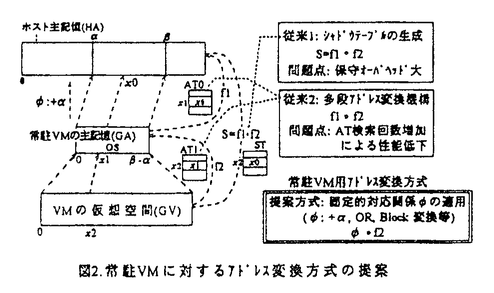
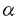 だけずらしてシステムの主記憶に常駐化させたものである(これをV=Resi属性と云う)。常駐VMは、主記憶サイズの許す範囲内で複数台定義可能である。このメモリの割当て方自体は新しいものではなく、
だけずらしてシステムの主記憶に常駐化させたものである(これをV=Resi属性と云う)。常駐VMは、主記憶サイズの許す範囲内で複数台定義可能である。このメモリの割当て方自体は新しいものではなく、