音声認識のアプローチには、基本的な認識の単位を、意味をになう最小言語単位である単語とする方法と、単語より小さいサブワード(音節、音素など)とする方法とがある。後者の方が大語彙音声認識に適したより一般的なアプローチであるが、音声のスペクトル構造は調音結合と呼ばれる現象により前後の音素環境の影響を受けて変形するので、前者のように認識単位を大きくとる方が調音結合によるパターンの変動が少なくなり、より容易に安定した認識を行うことができる。本研究は、世界的にも音声認識の研究が緒について間もない1961年に開始されたが、音声認識技術の早期実用化を目指して、前者のアプローチにより単語を単位とした高精度の音声認識方式を確立することを目標とした。具体的には、(1)単語特徴抽出による不特定話者の数字音声認識、(2)パターンマッチングによる特定話者の連続単語認識、(3)識別関数による不特定話者の単語音声認識、という三つのサブテーマのもとで研究開発が進められた。 第1サブテーマでは、不特定話者用の数字音声認識装置の試作を行った(1961-65年)。当時の単語音声認識に関する先行研究では、ハードウェア技術としては真空管とリレーを用いており、大量の情報を扱うことができず、このため、単語音声の時間構造を十分反映しない特徴パラメータの使用を余儀なくされ、特定話者モードでも認識性能には限界があった。 このサブテーマは、ハードウェア技術として、当時ようやく利用可能となったトランジスタによるディジタルおよびアナログ回路を使用することによって、より多くの情報量が利用可能となることを前提とし、音声認識の実用化への最初のステップとして、認識対象を不特定話者の数字音声に限定するという制約条件の下で、高い性能の認識装置を実現することを目指したものである。認識方式としては、低次フォルマントなどのロバストな音声パラメータから導かれる8個の単語特徴を抽出し、これらの特徴の生起状況から推定される事後確率が最大となる数字を決定するという独自の認識方式を採用した。このように、目標を限定し、それに適合した認識方式を用いたことによって、20名の話者を対象とした不特定話者モードの認識実験で97.9%の認識率を得た。本装置は、簡単なゼロクロス計数によるフォルマント抽出と、抵抗マトリクスによるアナログ的な事後確率の計算とにより、比較的コンパクトな実時間認識装置として実現された。この研究により、不特定話者の数字音声認識の性能は初めて実用レベルに到達したといえる。 第2サブテーマでは、パターンマッチングによる特定話者の連続単語認識の研究を行った(1968-84年)。先行研究において単語単位の認識方式による連続単語認識が試みられた例はなかったが、本サブテーマでは、まず最初に時間的な順序関係を反映する時間正規化マッチング尺度を新たに開発し、それを用いて最大マッチングの原理により連続単語のセグメンテーションと認識を同時に行う方法を提案した。この方法による連続単語認識方式は一応良好に動作することが示されたが、いくつかの原理的な問題点が残されていた。その第一はマッチングが局所的な最適化の積重ねにより行われるため、マッチングを誤る場合があること、第二は最大マッチングによるセグメンテーション点の決定は、類似度を始端から走査し、最大点を検出することによって行われるので、多少の誤差は免れないこと、また、第三は連続単語の単語境界付近の音声パターンが調音結合により変形するため、認識精度が低下することであった。これらは本研究の中で引続いて検討が続けられ、それぞれ以下のように解決された。 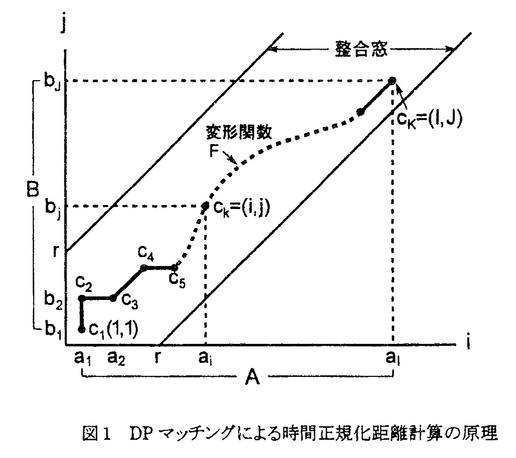 図1 DPマッチングによる時間正規化距離計算の原理 図1 DPマッチングによる時間正規化距離計算の原理 第一の問題点に対しては、新たに動的計画法(DP)を用いて大域的に最適化されたマッチング尺度(距離)を計算するDPマッチングと呼ぶ手法を開発した。これによりパターンマッチングの精度が大きく向上した。図1にDPマッチングによる二つの音声パターンA,B間の時間正規化距離計算の原理を示す。 第二の問題点に対しては、DPマッチングを二つの単語にまたがって適用することにより、厳密なセグメンテーションを行うことなく連続単語の認識を可能とする方法を開発した。これによってこのセグメンテーション誤差の問題はほぼ解決された。 残る第三の問題点に対しては、調音結合効果を含む半単語対標準パターンを用いる方式を開発した。これにより、認識語彙に制約があるものの、この問題も一応解決された。 DPマッチングによる連続単語認識の評価として認識実験を行った結果、特定話者の二桁連続数字に対して99.2%の認識率を得た。これは、特定話者の連続単語認識が実用レベルの性能に到達したことを意味している。また、特に連続発声数字の認識性能の改善に主眼をおいて開発した半単語対標準パターン方式による、別の話者を対象とした実験では、1〜5桁の連続数字に対する誤り率が、通常の単語標準パターンの場合の2/3以下になることが示され、大きな改善効果が認められた。 DPマッチング方式の実用可能性を実証するため、小型コンピュータと高速プロセッサから構成されたシミュレーション用のシステムと、ミニコンピュータをベースとし、DPプロセッサを付加した可搬型のシステムの二つの実時間認識システムを試作した。これらのシステムを用いて各種の評価実験が行われた。また、これらのシステムの試作結果に基づき、さらに小型化、高性能化を進めることによって、2チャネル入力が可能な卓上型のモデルが開発されたが、これは連続単語認識装置として世界的にも最初の実用機であるDP-100の直接の原型機となった。その後、DPマッチングLSIの開発も行われ、各種製品に使用された。これらの製品は多くの工場、作業所などで、仕分装置、クレーンなどの各種機器の制御や、検査データ入力などの作業に用いられ、このような応用分野における音声入力の有効性を実証した。 第3サブテーマでは、識別関数による不特定話者の単語音声認識の研究を行った(1965-85年)。具体的には、単語音声パターンを特徴空間における点として表し、学習サンプルの点集合を完全に分離する区分的線形識別関数を線形計画法を用いて逐次的に計算するアルゴリズムを開発した。この方式では、第1サブテーマの方式と異なり、特殊な単語特徴抽出は必要なく、一般的な周波数分析パラメータを用いて、大量の学習サンプルに基づいて識別関数を計算することにより、原理的にはいくらでも認識性能を上げることが可能となる。このような区分的線形識別関数の構成法は、先行研究例がなく、本研究で初めて実現されたものである。 この区分的線形識別関数は、線形計画法を用いてサンプルを線形可分なサブクラスに分けながら、線形2分法を繰り返し適用することにより計算される(図2参照)。このため計算量の負担はかなり大きいので、大量の学習サンプルを用いて効率的に計算が行われるように、サンプルを前以て凸面上に写像することで、線形識別関数を用いて等価的に非線形(2次)識別関数を構成する、いわゆる 関数法を導入したほか、学習サンプルを多段階に分割することにより線形計画法の計算を常に主メモリ上で行う方式を開発し、また、100語程度の中語彙認識において高い認識精度を維持するために、単語構造テーブルを用いて時間軸の整合と情報圧縮を行う方式を開発するなどの改良を加えた。認識評価実験の結果、不特定話者の100語に対して99%の認識率が得られ、実用可能性が実証された。 関数法を導入したほか、学習サンプルを多段階に分割することにより線形計画法の計算を常に主メモリ上で行う方式を開発し、また、100語程度の中語彙認識において高い認識精度を維持するために、単語構造テーブルを用いて時間軸の整合と情報圧縮を行う方式を開発するなどの改良を加えた。認識評価実験の結果、不特定話者の100語に対して99%の認識率が得られ、実用可能性が実証された。 不特定話者音声認識によく用いられる電話音声に適した簡略化音声分析法として、多値ウォルシュメルケプストラムを提案した。これは乗算をまったく必要としない方法でありながら、通常のメルケプストラムに匹敵する認識性能が得られることが示された。この方法により、ディジタル信号処理プロセッサのような特別のハードウェアを用いることなく、高性能な汎用マイクロプロセッサにより音声認識システムを構成することが可能となった。 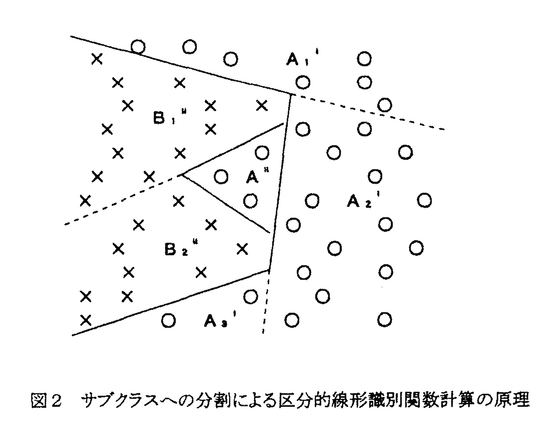 図2 サブクラスへの分割による区分的線形識別関数計算の原理 図2 サブクラスへの分割による区分的線形識別関数計算の原理 この識別関数による認識方式の各種評価を行うため、100語程度の中語彙を対象とした二つの実時間音声認識システム、すなわち音声認識パイロットモデルと音声認識プロトタイプ、を開発し、また、各種電話サービスシステム用の小語彙の多回線電話音声認識装置を開発した。 音声認識パイロットモデルは、市販のミニコンピュータ、アレイプロセッサ等を組み合わせて構成したもので、準リアルタイム動作を確認した。認識性能としては、FORTRAN/BASIC言語を対象とした100語に対して、99%の認識率が得られた。 音声認識プロトタイプは、専用の高速プロセッサ等を新たに設計してマルチプロセッサシステムを構成し、卓上形の筐体に実装したものである。認識方式は音声認識パイロットモデルと同一であり、リアルタイム動作を実現している。本プロトタイプを実際に国鉄(当時)の新幹線座席予約システム「マルス」に接続して、電話音声対話により座席予約を行うシステムを作成し、評価実験を行った。その結果、この種の電話音声入出力システムの実用可能性が確認された。 これらの成果に基づき、各種の電話音声入出力システムへの適用を目的とした多回線電話音声認識装置を開発した。この装置では、認識語彙を数字を主体とした16語に限定したことにより、比較的単純なハードウェア構成で高い認識性能を実現している。本装置には、認識処理部を多くの回線に対して時分割多重利用するためのマトリクススイッチが内蔵されており、1回線当たりの音声認識のコストを数分の1に低減している。本装置を中心とし、音声応答装置等を加えて構成された多回線用電話音声入出力システムは、その後、残高照会サービス等を行う電話サービスシステムとして多くの銀行等に導入され、業務の省力化やサービス向上に貢献した。 |