| 内容要旨 | | 1964年のIBM360シリーズの登場以来30有余年,汎用大型コンピュータは社会の基幹システムを構成する必須のコンポーネントとして発展してきている.この間,高速高集積LSI・実装技術の進歩に支えられつつ,キャッシュ記憶やパイプライン方式等による処理速度の向上,仮想空間導入やアドレス拡張によるデータ規模の拡大,多重化システム技術による信頼性の向上等,各種の工夫により高い処理能力と信頼性を実現するに至った. 本論文は,こうした様々な工夫の内,特にプロセッサ本体の命令処理速度改善に着目して開発した各種の命令レベル多重実行方式に関し,商用マシンへの適用例に即して報告,併せて今後の開発の方向に資することを目的としている. プロセッサの処理速度を1秒あたりの命令実行数MIPS(単位:100万命令/秒)で表わすと,これは次式にて表現できる. MIPS=1/(CPI xTmc) ここで,CPIは平均命令処理サイクル数,Tmcはマシンサイクル時間(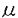 秒)である.Tmcは主として回路実装技術と演算処理アルゴリズムとにより,CPIは主として論理方式とオブジェクトコード生成技術により改善される. 秒)である.Tmcは主として回路実装技術と演算処理アルゴリズムとにより,CPIは主として論理方式とオブジェクトコード生成技術により改善される. オブジェクトコードの改善は新しい命令スケジュール機能を備えたコンパイラによりソースプログラムを再コンパイルする方法によるのが現実的であるが,汎用コンピュータ上の膨大なソフトウェアのそれぞれについて,これを行うことは必ずしも容易ではない.このため,汎用コンピュータでは新しいプロセッサの性能は同一オブジェクトに対する処理速度の改善度にて評価するのが一般的である.従って,この研究ではオブジェクトコードの改善を含まず,論理方式のみによるプロセッサ高速化に着目している. 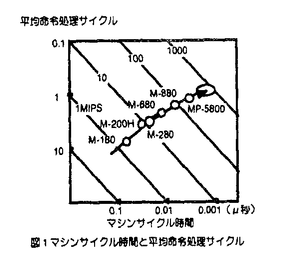 図1 マシンサイクル時間と平均命令処理サイクル 図1 マシンサイクル時間と平均命令処理サイクル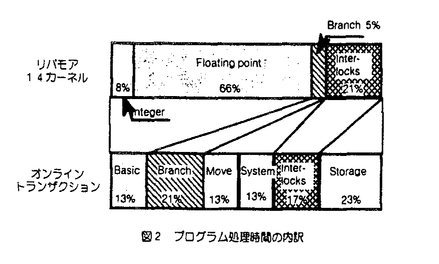 図2 プログラム処理時間の内訳 図2 プログラム処理時間の内訳 図1は過去20年間の汎用大型コンピュータにおけるMIPS,CPI,Tmcの移り変わりを示した例である.また,図2は最近のマシンにおけるTPIの内訳を科学技術計算とビジネスの各分野につき示した例である. 1)命令レベル多重実行方式(1)スーパパイプライン方式 複数の命令を同時に実行する方法として命令実行回路を時間的に多重化したのがパイプライン方式であるといえる.同時実行可能命令数はパイプラインステージ数に等しいので,ステージ数Nを多くすることで高速化が期待できる.この場合,マシンサイクルTmcが実効的に短縮される.この考えに従ってステージ数を通常の2倍程度に増やしたのがスーパパイプライン方式である. しかし,ステージ数の増加に伴いシーケンシャルに実行される事象の処理サイクル数も増加するため,この分のCPIの増加を考慮に入れる必要がある.すなわち,MIPS向上の方法としてステージ数Nを多くすることは自明ではない.そこで,以下では,回路実装系とプログラムが与えられたときに,MIPSを最大にするステージ数Nを求める簡便な方法を提供すると供に,商用マシンを対象にスーパパイプラインの効果を定量的に評価する. まず,ステージ数Nに対するマシンサイクルTmcは,マシンにおける分岐命令処理のルートを対象に設計上無理のない位置にパイプラインレジスタを設けたとして,このルートに関する遅延時間評価を行うことで見積もる.このルートを選択する理由は,本ルートが処理時間の多くを占める分岐命令処理に関わること,本ルートには命令解読やアドレス加算等の多数段の論理素子とキャッシュ記憶等を構成する超高速メモリ素子が含まれており,論理方式並びに回路実装技術のいずれの観点からもマシン開発上最も注力する論理の一つであることによる. 次に,評価対象プログラムの命令トレースやハードウェアモニタ等の解析により,命令やそれに関わるメモリ参照,パイプラインインターロック等の各種事象の頻度を取得する. これらの内,シーケンシャル事象の処理につき,ステージ数Nに対する処理時間の増加率を見積もる.これは上記分岐命令処理ルート全体の処理時間のNに対する増加率で近似するのが簡便である. 以上からNに対する全てのシーケンシャル事象の処理時間が見積もれる. パイプライン実行可能な事象に関する処理時間は当該事象の頻度とマシンサイクル時間から容易に求まる. 以上から,ステージ数Nに対して評価対象プログラムの処理時間を見積もることができ,商用マシン開発にあたってこの手法を適用した例を図3に示す.これから最適性能を与えるNが得られることがわかる. スーパーパイプラインはステージ数Nが7〜8以上に相当すると考えると,同図の前提においては高速化に対し効果的ではないといえる.  図3 プログラム処理時間と分岐処理ルートステージ数 図3 プログラム処理時間と分岐処理ルートステージ数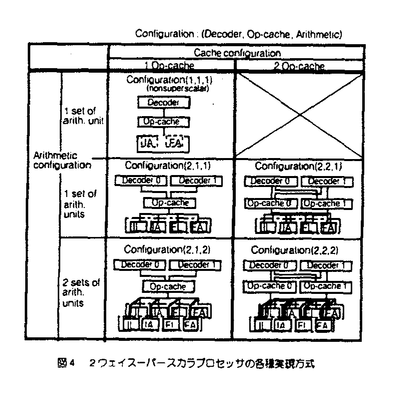 図4 2ワェイスーパースカラプロセッサの各種実現方式2)命令レベル多重実行方式 (2)スーパスカラ方式 図4 2ワェイスーパースカラプロセッサの各種実現方式2)命令レベル多重実行方式 (2)スーパスカラ方式 上記1)よりパイプラインステージ細分化を行うと,シーケンシャル事象処理時間の増加による全体性能への悪影響が問題となり,仮に従来のマシンの2倍程度に並列度を上げようとすると返って性能低下をもたらす可能性の高いことがわかった. シーケンシャル事象処理時間の増加をおさえた上で,より多数の命令を同時に実行する方式としてパイプラインを複数設ける空間多重実行方式があり,スーパスカラ方式として最近では一般的となっている.著者らは,汎用コンピュータにおける2多重スーパースカラ方式として,オペランドキャッシュの個数,演算ユニットの個数をパラメータとした各種実現方式(図4)を対象に,その効果に関し評価を行った.すなわち,本来スーパスカラ方式のもつ高速化の効果と,主要プロセッサ資源を節約して実現した場合に生ずる並列実行制限が処理速度にどの程度影響するかを定量的に評価し,よりコスト効果の高い実現方式を明らかにすることが狙いである. 命令トレースを入力としたステージシミュレーションにより,CPIの短縮効果を評価,また同時実行のための論理回路付加によるマシンサイクル増加の影響を見積もり,商用マシンにおける総合的な性能改善効果を評価した.これをハードウェアのコストに対しプロットしたものが図5である.評価は科学技術計算とビジネス系の2分野に関して行った. 科学技術計算の例ではオペランドキャッシュと演算ユニットをそれぞれ2組設けた場合,マシンサイクルへの影響を考慮しても26%以上の効果が得られたのに対し,ビジネス応用の例では4%程度とわずかであった.科学技術計算の場合,各資源を順に節約していった場合でも,構成により10-20%程度の効果が期待できることも明らかになった.ハードウェアコストの増加に対し,10%程度以上の性能向上効果が期待できるのは科学技術計算において,オペランドキャッシュのみ2組もつ構成と,いずれも1組のみからなる構成であるとの結果を得た.ビジネス応用の例ではいずれも性能・コスト比は単一パイプライン方式に比較して低下するとの結果を得た. ビジネス応用では,シーケンシャル処理が必要な命令や事象が高頻度で出現するため,並列実行によるCPI改善効果が全体として小さな割合であることが問題である.このため,この分野では分岐命令処理,システム制御命令,メモリ参照等の,各種項目に関する改善をそれぞれ積み重ねることが重要であることがいえる. 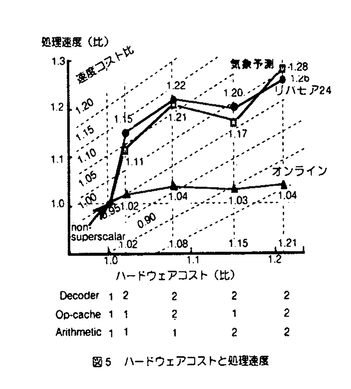 図5 ハードウェアコストと処理速度 図5 ハードウェアコストと処理速度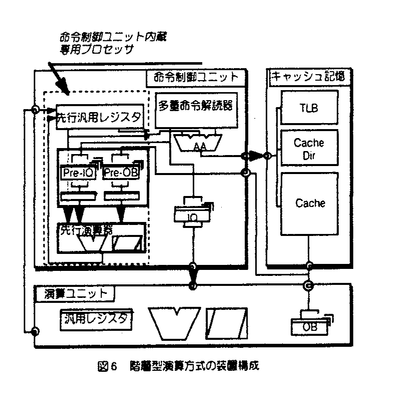 図6 階層型演算方式の装置構成3)階層型演算方式 図6 階層型演算方式の装置構成3)階層型演算方式 図2で示したプログラム処理の内訳でわかるように,アドレス生成インターロックや条件分岐命令処理の短縮が重要である.これらは本質的に複数命令間の依存性からくるシーケンシャル事象で,その解決方法としては a)その事象そのものの処理時間を短縮する, b)その事象をより早期に検出し,早い時点から処理を開始する, ことがポイントである. a)の実現手法としては従来よりデータバイパスや簡単な専用演算回路の設置による手法が開発されてきた.b)の実現手法としてはマシンによるダイナミックな命令スケジューリングが考えられ,商用マシンとしては古くは360/91にその例をみることができる.しかしながら,370アーキテクチャに基づく汎用コンピュータでは,命令の概念的な実行順序の保証規定から,いわゆる命令の非順次実行を実現した例はなかった. そこで著者らは,図6に示す非同期先行演算を可能とする階層型演算方式を開発した.すなわち,命令制御ユニットにアドレス生成によく使用される命令を処理する小規模専用プロセッサを設け,当該命令を後続の命令より非同期先行的に実行可能としている.このため,この専用プロセッサは先行演算器の他に,先行汎用レジスタ,先行命令キュー等を有する.命令解読器はプロセッサ本体と共用するが,M-680の場合毎サイクル2命令ずつ解読可能とすることで,インターロックの原因となる命令を早期に検出し,早期に処理開始可能としている.解読後,プロセッサ本体の演算ユニットの空きをまたずして,先行演算器にて演算,結果を先行汎用レジスタに格納する.割り込み発生時の順序保証のために,当該演算は後刻演算ユニットにて再度実行され,本来の汎用レジスタにはプログラムの実行順序にしたがって格納する.割り込みが発生した場合,専用プロセッサ内の先行汎用レジスタは本来実行されないはずの後続命令の結果が既に格納されている可能性があるため,本来の汎用レジスタをコピーすることにより,割り込み時点での内容に回復する. 以上のような制御により,アーキテクチャの規定による命令実行の順序性を保証しつつ,命令の非同期先行演算(非順序実行)により,アドレス生成インターロックや条件分岐命令処理の待ち時間短縮を実現した.本方式も命令レベルの多重実行方式の一形態と考えることができる. 非同期先行演算を含む階層型演算方式の効果を商用マシンにて実測した例を図7に示す.当該方式がないモードに対して平均で10%の処理速度改善効果を確認した. 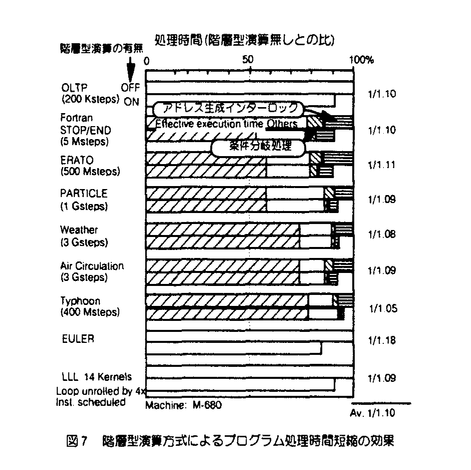 図7 階層型演算方式によるプログラム処理時間短縮の効果 図7 階層型演算方式によるプログラム処理時間短縮の効果 以上,命令レベル多重実行方式として3方式を提案し汎用大型コンピュータに適用,その有効性並びに限界を評価した. |