| 内容要旨 | | 1.新しい人間-機械系を目指して これまでの人間-機械系音声応用システムでは,機械への入力の単純な代替手段として音声を利用するものが多く,しかも,語彙や文法,語の意味,さらには発話単位や発声タイミング等に大きな制限が課せられている.結果的に人間には機械との対話自体が非効率な印象を与えかねない.従って,いかに人間に制約や負担を与えずに「自由に」発話できる環境を提供できるかが,最重要課題と考える. 人間の音声を用いたコミュニケーションを振り返ってみると,人間は漠然とした考えを起点に,言葉を選びながら発声に変えていく.発声の途中でも思考が中断することはない.このプロセスには,音声言語の持つリアルタイム性,連続性等が内包されており,このリアルタイム性,連続性があって初めて人間は気軽に音声を利用できるのだと考える. 本研究では,人間に負担を与えない人間-機械系を目指し,人間がいつでも発話でき,適切な反応が即座に得られるような環境,すなわちリアルタイム性と連続性を内包する自由な発話環境の提供を図った.本論文では,この新しい人間-機械系の枠組みを「時間連続音声認識パラダイム」と呼び,その提案を行う.そして,本パラダイムが提供する新しい応用領域について述べる. 2.時間連続音声認識パラダイムとそのアルゴリズム(1)時間連続音声認識パラダイム 時間連続音声認識パラダイムは,音声言語の持つリアルタイム性,連続性を内包したコミュニケーション・プロセスを実現するものであり,人間同士のコミュニケーション形態を人間-機械系においてもサポートすることができる.利用者は1人に制限する必要はなく,複数の人間が「同時に」システムを利用でき,人間同士の討論を機械が認識/理解し,その応答を行うことができる.本研究では図1のように,目と耳と口を持った機械が複数のユーザの議論に参加し,人間の思考や発想,協調的作業を支援することを目指している.時間連続音声認識パラダイムでは,一発話のみならず,時間的に連続した音声(連続時間音声)を対象とすることになり,音声研究分野としては右表の斜線円で示した領域をターゲットとするものである.  図1.計算機と複数のユーザの対話 図1.計算機と複数のユーザの対話 表1.音声認識研究の分類 表1.音声認識研究の分類 時間連続認識パラダイムは,音声以外の時系列データに対して適用が可能であり,動画像への適用を試み新しい応用領域の開拓を目指していく. (2)時間連続音声認識アルゴリズム 時間連続音声認識アルゴリズムでは,入力から結果出力までの全ての処理をリアルタイムに実行する必要がある.また,「いつ入力(発話)してもよい」ということは,無限の長さ,すなわち連続する入力情報に対して,常に各時刻で処理を全て完結させる(処理完結性)必要がある. 多くの音声応用システムでは,検出した音声区間に対し,その開始時刻を最初の仮説として認識アルゴリズムが始動する.これを始端仮説アルゴリズムと呼ぶ.一方,講演などの時間的に連続する連続情報を処理するためには,始端仮説が生成できないため,終端仮説に基づく処理方式が必要になる. スポッティング方式は,終端仮説方式であり,さらに,上述したリアルタイム性,時間連続性,および処理完結性を損なうことはない.図2に始端仮説方式と終端仮説方式の概念を示した.終端仮説方式では,現時刻を発話の終りと考え,どのような入力がいつ行われたのか,現時刻から時間反対方向へ評価することになる.本研究では,前述のリアルタイム性,時間連続性を実現するために,「DPの原理を保持した現時刻終端仮説方式」をアルゴリズム上で実現する.  図2.始端仮説方式と終端仮説方式の概念3.提案する時間連続音声認識アルゴリズムと新しい応用領域 図2.始端仮説方式と終端仮説方式の概念3.提案する時間連続音声認識アルゴリズムと新しい応用領域 本論文では,3つの時間連続音声認識アルゴリズムを開発し,紹介した.以下に,各々のアルゴリズムの概要と,それにより展開される新しい人間-機械系について述べる. (1)連続パターンスポッティングLadder連続DP(LCDP)法の提案 人間の自然な発話では,不要語が多く,文法が守られていない場合も多いために,言語的,意味的にまとまりをもった部分をスポッティング認識することが有効である.このための新しい枠組みとして連続単語スポッティング方式"Ladder CDP(LCDP)"法を提案する.この方式は一連の入力音声中に認識すべき単語列があればスポッティングを行う時間連続音声認識アルゴリズムである. Ladder CDP(LCDP)法の概念図を図3に示す.横軸を入力時間軸t,縦軸を標準パターンの時間軸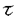 として,通常のワードスポッティングでは,n個の単語W1(1≦i≦n)を図の1st Stageとして配置する.LCDPは,n個の標準パターン(単語,文節等)を,図のように標準パターン側の縦軸方向に任意の個数積み上げて配置し,任意の個数のパターンをスポッティングできる枠組みである. として,通常のワードスポッティングでは,n個の単語W1(1≦i≦n)を図の1st Stageとして配置する.LCDPは,n個の標準パターン(単語,文節等)を,図のように標準パターン側の縦軸方向に任意の個数積み上げて配置し,任意の個数のパターンをスポッティングできる枠組みである. 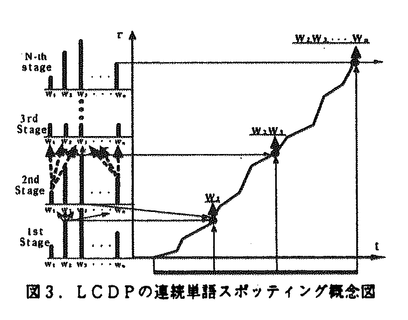 図3.LCDPの連続単語スポッティング概念図 図3.LCDPの連続単語スポッティング概念図 実験の結果,LCDPでは効率的に従来手法と同レベル以上の認識性能を得ることができた.会議等の人間同士のIll-formedな連続音声に対し,本手法によって展開可能な新しい応用領域を以下に示す. (1)連続音声からの表層表現の抽出:講演や人間同士の対話など従来システムでは対象とされなかった音声を入力とし,その中のある種の表層的表現のまとまりを把握することにより,内容を理解するものである.TVニュースを用いて実験を行い,その有効性を確認した. (2)音声検索:ビデオ検索のように長時間音声から,ユーザが所望する部分を選定した複数のキーワードから探し出すというもので,TVニュースを用いた実験の結果,誤った出力を抑止しながら,キーワードが連続的に発声された区間を抽出でき,連続単語スポッティングの有効性が確認できた. (2)時間連続処理に基づく部分マッチング応答方式RIFCDP 標準パターン中の任意の区間と入力音声中の任意の区間との共通する区間を,スポッティング検出する,時間連続音声認識アルゴリズムReference Interval-freeの連続DP(RIFCDP)を提案する.本方式では,任意の長さの一連の時系列データを標準パターンとして用いたため,標準パターンとして予めセグメンテーションする必要はない.本手法は,以下の応用事例に示したように,多くの応用領域を開拓できる基本アルゴリズムと位置づけることができる. RIFCDPのアルゴリズムを簡単に紹介する.図4に示したように,縦軸は標準パターン,横軸は入力を表す.RIFCDPでは,連続DPの原理に従って,標準パターン全体の最適パスを求める.標準パターンの各フレームでは,各時刻において,フレームを終端とするパスに対し,累積距離の履歴を全て保持することによって,フレームと任意のフレーム数前の区間距離を計算できる.この区間距離を,その区間の累積重み係数で正規化すれば,任意区間同士の整合度が求められる.  図4.RIFCDPの概念図 図4.RIFCDPの概念図 音声データを用いた実験の結果,共通音声区間の抽出が可能であることを示した.さらに以下の応用領域の可能性についても評価・確認を行った. (1)リアルタイム音声データベース検索:ユーザが思いついたキーワードやそれを含む文を自然な発話で入力し,検索に必要なキーワードが入力された時点で,瞬時に検索結果を出力する. (2)移動ロボットの時系列画像による位置同定:移動ロボットが一度走行して獲得した時系列画像データをRIFCDPの標準パターンとして用いることによって,同一場所を走行した場合には,どの標準パターンに対応するか,即ち自分の位置をリアルタイムに同定する. (3)要約や話題境界の抽出:何度も繰り返される重要語を抽出し,その話題の要約とする.また,重要語の出現分布から話題の境界を抽出する. (3)発話制限のない時間連続処理に基づく新しい人間-機械系 時間連続音声認識パラダイムでは,ユーザにはいつ発声してもよいという環境を提供できる.この環境では,ユーザは気軽に話すことができ,人間-機械系の音声インタフェースとして最も望まれているものの一つである.本研究では,時間連続音声認識パラダイムに則って,前述したようなコンピュータが複数のユーザの議論に参加し,ユーザの知的作業や協調的作業,発想を支援する新しい人間-機械系の構築を目指した.本システムでは,時間連続認識パラダイムのもと以下の機能を有する点に特徴がある. (1)音声とジェスチャのマルチモーダル環境 (2)ユーザはいつ発話しても可 (3)理解結果をリアルタイムに応答 (4)複数のユーザの利用 (5)ユーザの知的/創造的作業の支援 本システムでは,各ユーザにマイクロフォンおよびカメラを向け,それぞれ信号情報を音声認識部,動画像認識部でスポッティング認識を行い,連続オートマトンと呼ぶ時間連続音声認識アルゴリズムで現在の入力に最も合う概念のスポッティングを行う.スポッティングされた概念は,ユーザ側に即座にシステムの現在の理解状況として,グラフィクスを用いてリアルタイムにフィードバックされる. 本システムでは,タスクとして,一般ユーザが自分達の家の大雑把な配置を決定していくという「家の配置設計」を採用した.ユーザには家のグラフィックス画像が提示され,希望するイメージをユーザが言葉,あるいはユーザ同士の会話,ジェスチャで指示すると,即座に画像に反映されていく.本システムを実際に2人のユーザが利用している様子を図5に示す.被験者を用いた評価実験の結果から,時間連続音声認識アルゴリズムに基き構築した本システムの利用可能性,有効性を確認した.  図5.2人のユーザによる本システムの利用例4.結論 図5.2人のユーザによる本システムの利用例4.結論 人間-機械系音声応用システムにおいては,キーボードの単なる代替手段の実現を狙うのではなく,韻律性,個人性等の情報や,リアルタイム性,連続性,冗長性等の特徴を積極的に利用した新しい応用領域の開拓が必要であると考えた.そこで,本研究では,人間同士の会話に見られる,断片的,連続的な発声に対処できるような新しい人間-機械系を目指した.本研究では,このようなメカニズムを「時間連続音声認識」と呼び,その意義と実現方式,新しい応用領域を提案した. 時間連続音声認識パラダイムのもと,Ladder CDP法では講演,ニュース等の連続音声からの表層表現の抽出/検索,RIFCDPでは共通区間データの検出,音声データベースの音声によるリアルタイム検索,信号レベルにおける要約・話題境界の抽出,そして動画像にまで応用領域を広げ,ロボットの現在位置の検出など,様々な領域で応用が可能であることを検証した.さらに,複数のユーザによる会話/議論をサポートする新しい人間-機械系を構築し,本システムの利用可能性と時間連続音声認識パラダイムの有効性を確認することができた. これらの結果を踏まえ,本論文で提案した時間連続音声認識パラダイムは,人間-機械系における新しいインタフェース,新しい応用領域の開拓の可能性を与えるものであり,音声処理および情報処理の発展に寄与するものと考える. 今後,機能の強化・拡張は実利用化に向けての大きな課題であるが,さらなる応用領域の開拓が重要と考える.本論文で提案した時間連続認識パラダイムは,動画像等の音声以外にも応用できることを示したが,様々な展開の可能性を有しており,さらなる新しい応用領域の開拓を目指していきたい. |