関係データベースは、SQL言語による高い抽象レベルのデータベース演算機能を提供し、多くの分野での実用化が進んでいるが、高機能ゆえに大規模化に伴う性能の劣化が大きな隘路になりやすい。従来の関係データベースの高速化方式としては、高機能I/O方式や並列プロセッサ方式があるが、いずれも高い適用率の実現が難しく、アムダールの法則からコストパフォーマンスの改善に壁があった。本研究では、基本的には低レベルではあるが幅広い機能を有するベクトル演算機構を利用して高い適用率を実現し、安価な付加プロセッサ方式を採用することにより、コストパフォーマンスに優れた高速化方式を開発することが狙いである。大容量主記憶を前提として、ベクトル演算方式を用いた関係データベース処理高速化を実現するために、以下に示す3つの高速化基本方式を提案した。 (a)大容量主記憶を利用したDBキャッシュの大容量化による高速化方式 (b)簡潔化されたカラム単位一括化処理形態による高速化方式 (c)ベクトル演算命令適用による高速化方式 高速化方式(a)は、大容量主記憶上にDBキャッシュを実装することにより、表やインデクス情報を大容量主記憶上に常駐化し、I/O時間の大幅な短縮と、I/O起動に関連するCPU時間の削減も実現した。 高速化方式(b)は、従来のデータ形式とレコードを単位とする処理方式の問題点を解決するものである。従来のレコード単位方式では、「レコード更新時のI/O性能」と「必要な主記憶容量の少なさ」の点は優れているが、「手続き呼び出しの多発等に起因する低い処理効率」と「ベクトル化に適さない」などの点が問題があった。本研究ではこれに対して、ディスク上は従来のレコード単位の格納方式を採用して、ディスク上の互換性と更新処理でのI/O性能を踏襲しつつ、検索時にはカラムを単位としたベクトルを動的に生成する「動的カラムベクトル生成方式」を提案した。本方式により、手続き呼び出し回数の削減等による大幅な処理効率向上が可能となると共に、全件検索、インデックス検索、結合検索やインデックス生成などのベクトル化が実現できた。図1に、二表の結合検索を例題に、動的カラムベクトル生成方式による高速化方式の概要を示す。この例題では、効率的な突き合わせを実現するために、前処理として両表を部品番号に関してソートする。この図からも、ソートや突き合わせが重要かつ負荷の重い演算である事がわかる。 又、表に多数のインデックスが付与される情報検索分野での適用をはかるため、複数インデックス利用検索方式を導入し、複雑な検索条件を有する検索に対しても高いベクトル化率を可能とした。 高速化方式(c)は、数値演算を対象に開発されていた従来のベクトル演算機能を拡張し、関係データベースにおいても高い適用率(ベクトル化率)を実現した。ベクトル演算機能は、スーパーコンピュータに代表される数値計算分野では高速化を実現して大きな成功を収めているが、データベースの基本処理に適用した例はほとんど無い。従来のベクトル演算機能では、「オペランドの各ベクトル要素を指し示す添字(インデックス)が全オペランドに共通であるため、マージ演算が実現出来ない」、「ベクトル要素が単一値しか格納出来ないため、表構造を効率的に表現できない」などが問題点であることを指摘した。 この問題点に対して、本研究で提案する内蔵データベースプロセッサ(IDP:Integrated Database Processor)のアーキテクチャでは、「各オペランド別に添字」を持つことにより、ベクトル化マージ演算機能を提供する。マージ演算が対象とする各要素については、識別子を格納するフロント部とキー値等を格納するリア部を有する「デュアルベクトル(DV)形式」を考案した。前述の図1の例では、レコード識別子(ID)と、結合値である部品番号からなるDVを使用し、表全体をソートせずにDVのみをソートする効率化を図った。 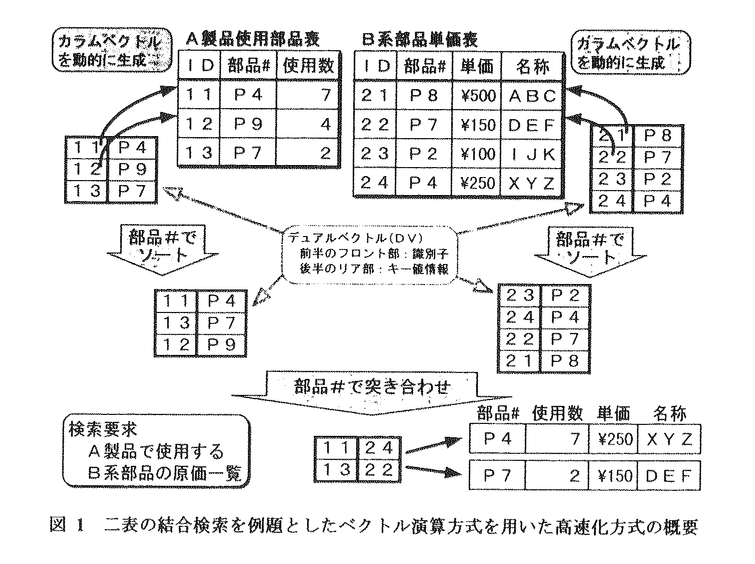 図1 二表の結合検索を例題としたベクトル演算方式を用いた高速化方式の概要 図1 二表の結合検索を例題としたベクトル演算方式を用いた高速化方式の概要 高速化方式(c)を実現するため、拡張されたベクトルアーキテクチャの持ったベクトル型データベースプロセッサ(IDP)のマージ演算機能を、既に数値計算向けのベクトル機能を有する汎用大型計算機M-680H上に、新たに拡張されたベクトル命令として実装した。本来は要素間に依存関係を有するマージ演算に対して、1比較1サイクルで実行する高並列パイプライン方式を開発した。開発規模としては、従来の数値計算用のベクトル機構を活用することにより、マージ演算をベースとした高速なマージソート命令、マージジョイン命令、サーチ命令を、プロセッサ本体の約5%のハードウェアの追加で実現し、付加プロセッサ方式の安価性を示した。 ベクトルアーキテクチャの実現方式に関してCPU時間について、性能上もっとも重要なソート処理の高速化の性能を評価した。主記憶上の内部ソートでは、新設のソート命令がスカラーの高速なクイックソート法と比較しても9倍近い高性能であることを実測した。また、プロセッサのバッファ容量を越える多量のデータ列に対しても、バッファミスによる効率の低下が少ない水平分割メモリソート方式の提案と、実測値での効果を示した。主記憶容量を越える超多量のデータに対しては、IDP命令(2ウェイマージ命令)による多ウェイ外部マージソート方式を提案し、性能を実測した。 製品レベルの実用化システムにおいて、上記の関係データベース高速化3方式のCPU時間に関する定量的な性能評価を、ベクトル化のオーバヘッドを含めておこない、新しい関係データベース処理方式が、コストパフォーマンスに優れた高速化方式であることを示した。結合検索を中心として設定したベンチマークでは、大容主記憶量による高速化方式(a)で1.1倍、簡潔化されたカラム単位一括化処理形態による高速化方式(b)では5.7倍、ベクトル演算命令適用による高速化方式(c)では2.4倍の性能向上を実測し、合計では15倍の性能向上を実現した。ソートリストを使用したDBキャッシュ管理方式によるページアドレス変換処理のベクトル化が、適用率向上に大きく寄与している。又、複数のインデックスを有効に利用する検索のベンチマークでは、若干のベクトル化のオーバーヘットが存在するものの、合計では3倍以上の高速化が実現できた。これらにより、動的なカラムベクトル生成方式がベクトル演算を用いた高速化方式に非常に有効であることを実証した。 性能評価の分析から、M-680H/IDPには改善すべき点がある事を指摘し、改善の効果をM-880/IDP上で確認した。M-680HのIDPでは最小限の機能に限定したため、ベクトル化とベクトル命令の適用は出来たが効率的でない点を解明し、重複排除機能、十進データ型、長いキー値等を、次機種であるM-880/IDPでは拡張した。この拡張により、殆どすべてのインデックス生成にIDP命令が適用可能となり、本来冗長なデータ形式変換や重複排除処理も無くすことができた。 ベクトル化のオーバヘッドと、ベクトル機溝すなわちIDP命令の適用効果の関係を定量的に分析した。ベクトル命令を適用するために、データ構造や処理アルゴリズムを変更するベクトル化では、オーバヘッドが新たに発生する可能性があることを指摘した。内部ソート処理、外部ソート処理、結合検索、複数インデックス利用検索、及び解探索での性能分析から、「データ形式の追加・変更」、「ループ制御等の処理形態の変更」、「アルゴリズム自体の変更」の3つの観点を用いて、ベクトル化に伴うオーバヘッド又は性能改善は、定性的な予測が可能であることを示した。 今後の課題としては、データウェアハウス(DWH:DataWare House)と全文検索が、本研究で提案するIDPの新しいデータベース分野への適用拡大の有望候補として挙げられる。関係データベースの中での適用分野拡大では、更新系SQLのベクトル化が今後は必要である。ベクトルアーキテクチャの将来方向としては、最高性能を追求した大規模な専用プロセッサ化だけでなく、IDPが不得意である「性能のスケーラビリティ」を改善するため、ベクトル方式と相補的な関係にある並列プロセッサ方式との統合が、今後は有望である。 |