本研究は、生物学的なデータベースからの知識発見に向けた手法について扱い、特に、同データベース内の互いに相関し合った要素が生物学的な現象に及ぼす効果を解明する技法の開発に主眼を置くものである。 生物学的なデータベースの解析に関しては、互いに相関した複数の要素の効果が注目されており、実際に多くの疾患、例えば、糖尿病や高血圧、卒中などは複数の遺伝的な要素(遺伝子)間の相互作用が原因となっていると考えられている。しかしながら、注目する生物学的な現象に有意な複数の要素の組合せを網羅的かつ効率的に求める技法あるいは、得られた「知識」を表現する技法の開発はこれまでに十分に行われているとはいえない。 一方、近年、意志決定支援システムあるいは、データマイニングシステムが強い関心を惹いており、大規模なデータの操作、意味解析に用いられている。この目的のために、決定木や、クラスタリング、結合規則を計算するための最適化手法が多く提案されている。これらの手法においても、データ内に存在する複数の属性間の相関関係の取り扱いの重要性が指摘されている。 このような背景を踏まえて、我々は、生物学的なデータベースから有意な相関要素を抽出することを主目的とした知識発見システムをデータマイニングの技法にもとづいて構築し、実際の生物学的なデータベースの解析に適用した結果によってその評価を行う。 本研究では、3種類の知識発見の手法を扱う。具体的には、 (1)複数の遺伝的要素の組合せと疾病の有無の関係の解析を意図した、統計的に最適な結合規則の探索 (2)複数の数値属性と疾病の有無の関係の解析を意図した、領域規則を用いたデータ分類 (3)複数の遺伝的要素の組合せと数的表現形の関係の解析を意図した、統計的に最適な結合規則の探索 である。 第2章において、最初の手法である、統計的に最適な結合規則の探索について述べる。まず、結合規則の有意さを評価する統計量を導入し、この問題を同統計量を最適化するグラフ探索問題として定式化する。探索の手順は書き換え規則として定義し、探索の並列化手法に焦点を当てる。 第3章では、領域規則の多数決を用いたデータ分類の手法を扱う。従来の分類手法では、主に分類精度の向上を目的としたものが多いが、本手法では、分類手法がデータから抽出した規則(知識)の可読性にも注目する。領域規則とは、図1に示すように2次元平面上の部分領域を用いてデータの分類を行うものであり、属性間の相関を直接的に表現できる利点をもつ。決定木、ブースティングといった従来手法との比較を行うことによって本手法の評価を行う。 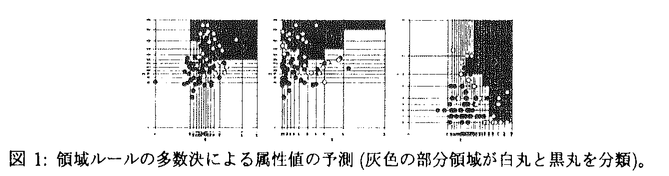 図1:領域ルールの多数決による属性値の予測(灰色の部分領域が白丸と黒丸を分類)。 図1:領域ルールの多数決による属性値の予測(灰色の部分領域が白丸と黒丸を分類)。 第4章では、複数の遺伝的要素の組合せと数的表現形の関係の解析を意図した、統計的に最適な結合規則の探索手法を扱う。同手法をOLETFと呼ばれる糖尿病のモデルラットのデータに適用して、複数のマーカの遺伝形の組合せと数的な表現形(血糖値と体重)の解析を行い、その結果(図2はその一部)について紹介する 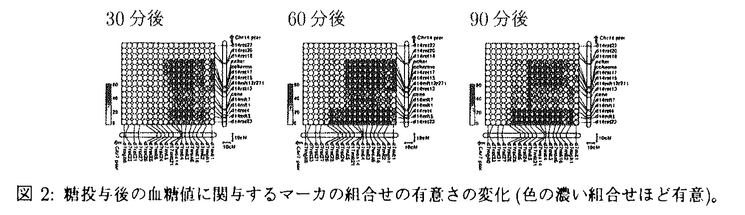 図2:糖投与後の血糖値に関与するマーカの組合せの有意さの変化(色の濃い組合せほど有意)。 図2:糖投与後の血糖値に関与するマーカの組合せの有意さの変化(色の濃い組合せほど有意)。 また、各節では、上記3種類の手法を最大128プロセッサを有する共有記憶型並列計算機上で実装し並列実行性能に関する評価を行う。 |